


Whoops... I failed and leaked the CEO's data
Building Multitenant RAG Architecture for Personalized Enterprise Content

⚠️ ᴀᴛᴛᴇɴᴛɪᴏɴ! ᴛʜɪꜱ ᴀʀᴛɪᴄʟᴇ ᴡᴀꜱ ᴡʀɪᴛᴛᴇɴ ʙʏ ᴀ ʜᴜᴍᴀɴ! ⚠️
The first time I heard about Retrieval-Augmented Generative Technology (RAG), I couldn’t fully understand its real use case. It took me some time to grasp its actual value.
The fact that RAG enables people to extend an LLM’s context window by dynamically injecting content from external sources has given companies with mostly private and proprietary data an immense advantage. Many of them have started pulling their data out of “underground storage basements” and finally putting it to use—whether by creating internal tools and services to automate operations or by monetizing their data.
AI trends move at lightning speed, leaving the real engineers behind to fix the mess. Learn how to not to run after trends and architect real solutions.
Table of contents:
Multitenant Architecture Overview
The Problem: Multitenancy Meets Generative AI
Real-World Case Study: Our Architectural Journey
Challenge #1: Isolation
The Database-Level Isolation Approach
A Hybrid Approach
Challenge #2: Internal Role-Based Access
Bonus Approach: One collection, many tenants
Conclusion
It’s fascinating how companies are now profiting from the data they’ve been gathering over the years. By building internal tools and services, they’ve created systems to improve ROI—either by automating their workflows or by selling their data in various formats.
However, not all companies possess the internal expertise or workforce required to build such systems. This is why they usually take one of two alternative paths:
1. Outsourcing these activities: Paying external companies to develop these tools.
2. Searching for pre-existing solutions: Looking for already-built tools from other providers that match their use cases.
This article focuses on the second case—targeted toward engineers interested in learning how to build systems that companies can use to manage their immense data sources while creating a semantic knowledge layer over their information.
The key here is privacy, and what better way to address this important requirement than by implementing a multitenant architecture?
1. Multitenant Architecture Overview
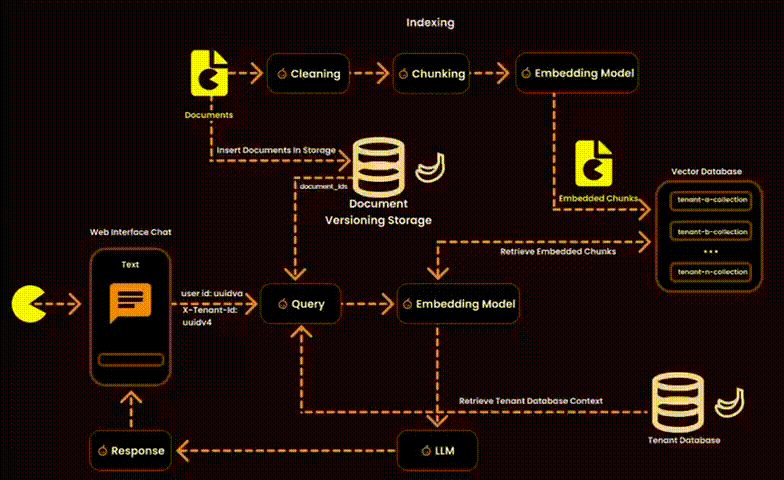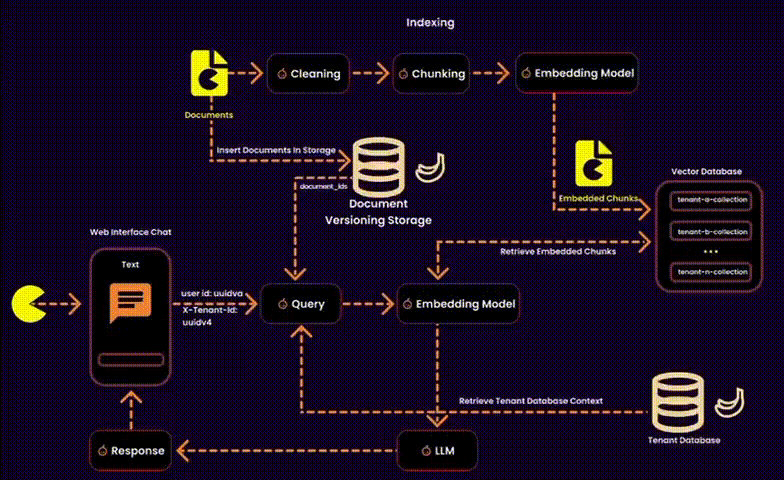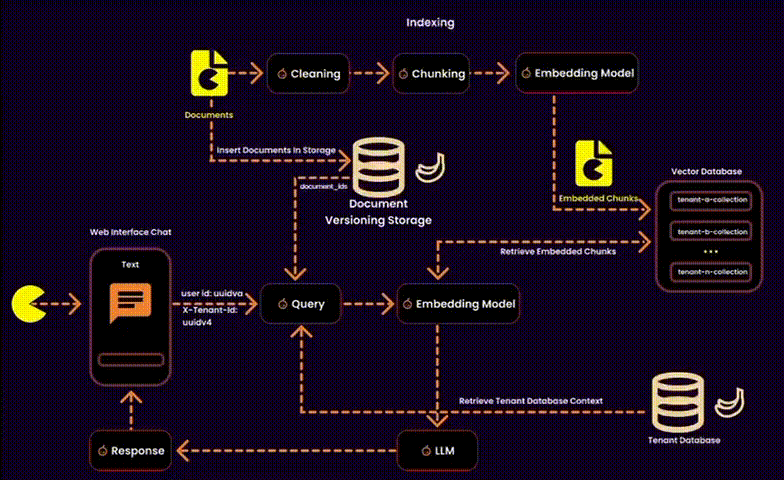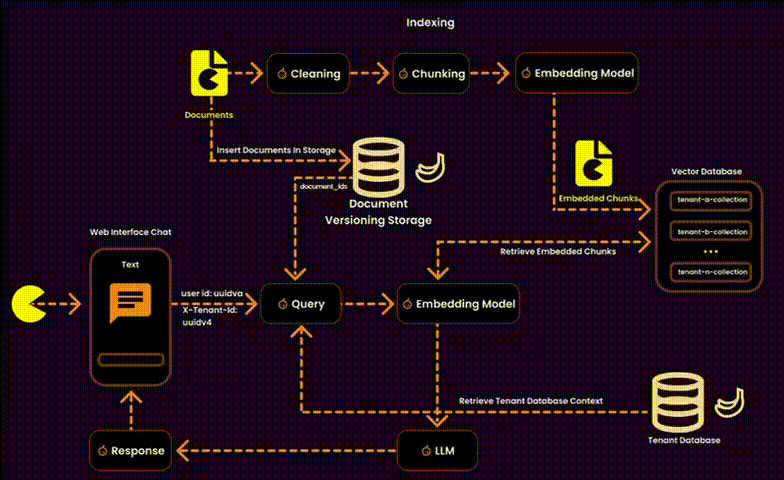
For those unfamiliar with the characteristics of a multitenant architecture, here’s a brief overview:
Historically, multitenant architecture revolutionized SaaS (Software as a Service) solutions in their early days. It allows a system to host multiple tenants, teams, users, or businesses on a single shared infrastructure, with each tenant sharing a portion of the resources. This design made scalable software more affordable and accessible.
A simple analogy: Imagine a building with multiple apartments. Each apartment is rented by a family or individual, who only pays for their own unit and its utilities. The building itself is shared by all.
2. The Problem: Multitenancy Meets Generative AI
Now, let’s get back to our main problem. Generative AI isn’t just about creating impressive content or tools that solve business challenges—it’s about delivering contextual solutions for specific users or companies. In simpler terms, tenant awareness is crucial.
Here’s the twist: Generative AI systems are fundamentally different from traditional SaaS. They don’t just store data—they retrieve, process, and generate knowledge in near real-time. This dynamic nature makes designing for multitenancy far more challenging—and exciting.
3. Real-World Case Study: Our Architectural Journey
Let me explain this with a real-world case I recently faced. I’ll present the architectural decisions my team and I spent days iterating on.
3.1 Challenge #1: Isolation
Isolation is one of the most critical challenges in multitenant architecture. It ensures privacy so that no tenant can access another’s private data. There are various techniques to achieve this, each with its own trade-offs.
Requirement #1: The solution was for to enterprise clients and they take security very seriously. We had to build a rock-solid isolation system that could meet their demands.
In the context of RAG, this also involves managing embeddings—essentially designing a vector database for a multitenant SaaS platform. This requires balancing data security, operational efficiency, and resource management.
The Database-Level Isolation Approach
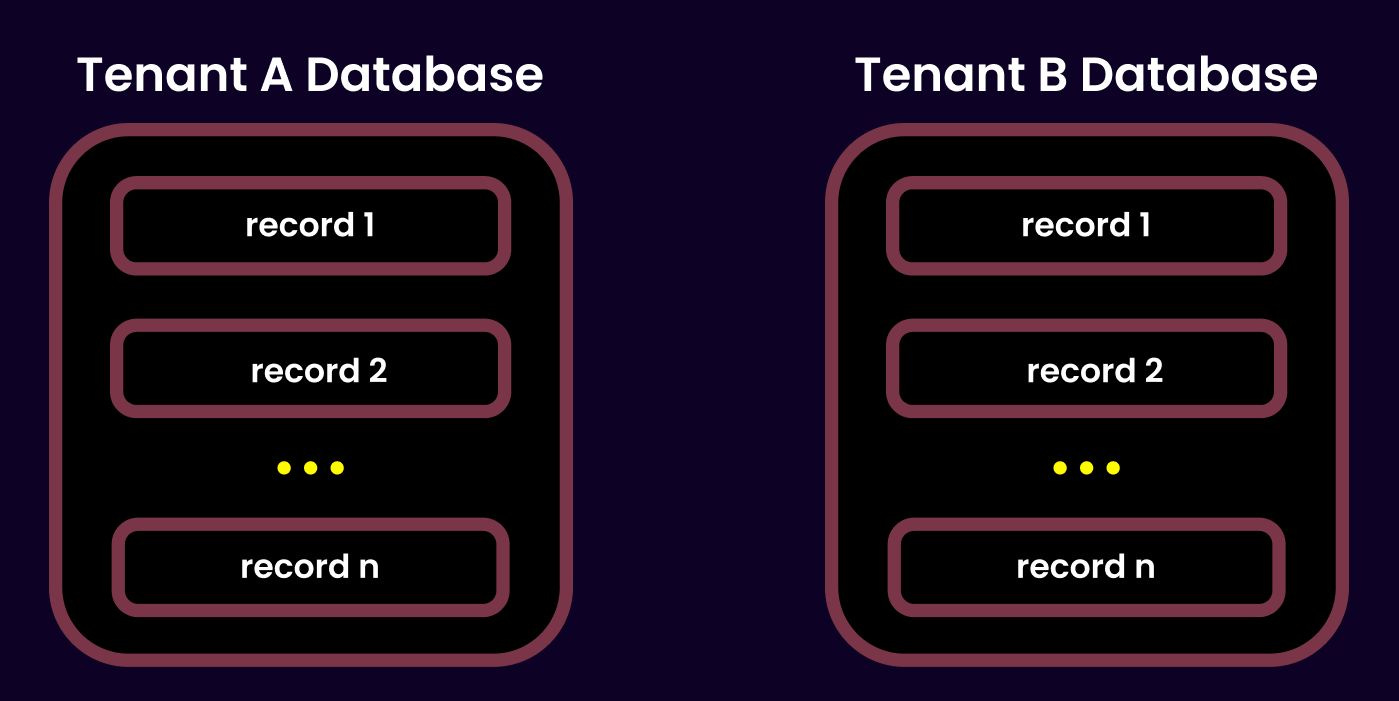
My first instinct was to apply database-level isolation, which is often considered the gold standard for data security. In this approach, each tenant gets its own database—end of story. It’s like giving every tenant their own private vault.
Pros:
• Zero data leakage: There’s no chance of cross-tenant breaches.
• Fine-tuning: Each database can be tailored to a tenant’s unique needs.
Cons:
• Wasted resources: Not all tenants will fully utilize their database’s capacity, leading to resource waste.
• Operational overhead: Maintenance tasks like upgrades and backups must be performed separately for each database, which becomes a nightmare with hundreds or thousands of tenants.
• Complex analytics: Cross-tenant insights require querying each database in parallel, which is both messy and time-consuming.
In short, while database-level isolation is extremely secure, it felt too heavyweight for our product’s current stage.
Before diving in the next approach, I’ll share a bit of wisdom with you:
I always design my architectures to be easily adaptable to any situation, or at least try … this gives me the ability to accommodate the system to any spontaneous changes that the business shareholders would make,.
Since it was an early stage of the product , it had an small taste of unpredictability , any client interview could’ve changed the course of the product. Let me break down some things that I’ve anticipated:
On-premise deployments: Some high profiled clients won’t risk to share their precious data on the same database that their competition may also use.
Selling to small groups or any individual user: Beside B2B maybe the product team along with the CEO would want to extend the solution to B2C.
A Hybrid Approach
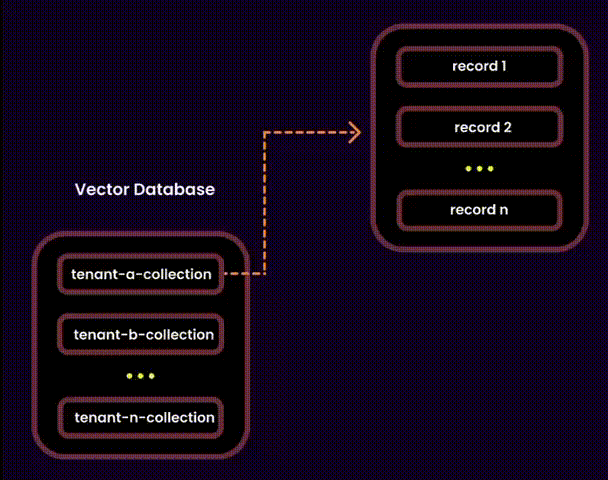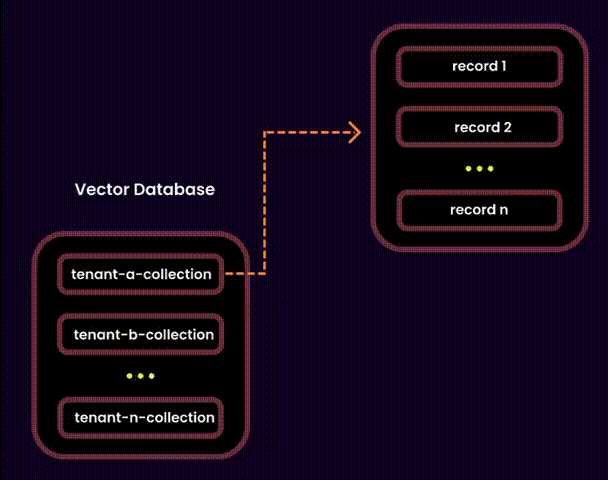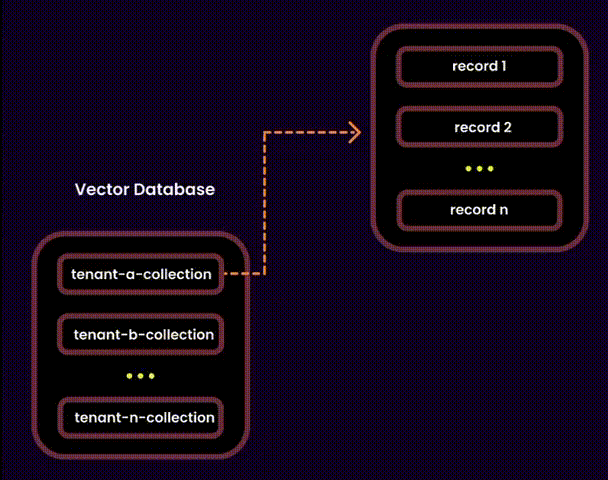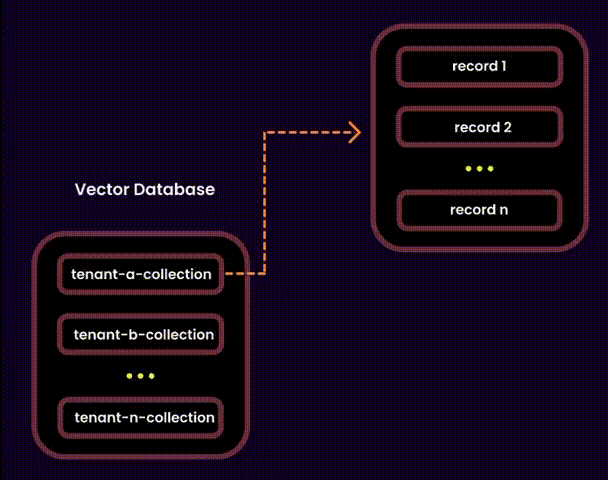
To address the challenges of unpredictability and scalability, I opted for a hybrid approach. This allowed us to combine the best of both worlds:
We created one embedding collection per tenant inside a shared database. Each tenant’s embeddings were logically separated into their own collections, ensuring privacy and adaptability.
Disadvantages:
• Uneven resource allocation: Tenants with larger storage needs could create performance bottlenecks. This can be mitigated by sharding the database and redistributing data as it grows.
• Cross-collection risks: Misconfigurations could lead to accidental data exposure. To counteract this, we used tenant-level RBAC policies and strict query filters.
• Shared resource dependency: Since tenants share the same database instance, issues like downtime could affect all tenants. However, implementing a high-availability setup ensures fault tolerance and removes single points of failure.
I started this way just to prepare you for the immense advantages that this architecture gave to use, remember, architecture is just about tradeoffs, and it’s very contextual, build to be fitted on an specific problem that your software is facing.
Now the advantages, compared to the last approach:
Advantages:
• Logical data separation: Cross-tenant breaches are highly unlikely.
• Operational efficiency: Backups and updates can target individual collections, reducing maintenance overhead.
• Flexibility: High-profile clients could still opt for dedicated databases, while smaller tenants could share resources.
• Scalability: Adding shards and redistributing data makes it easy to handle growth.
This hybrid approach prepared us for unpredictable changes while ensuring the system could adapt to various client needs.
3.2 Challenge #2: Internal Role-Based Access
Requirement #2: Employees in the company cannot access data from people holding high roles. So in plain English, your CEO or CFO won’t allow you to see classified company data, like P&L data and salaries.
One potential solution was to index user IDs in the metadata of each embedding (as suggested by Qdrant). However, this added unnecessary overhead to the metadata, so we explored alternative methods.
Our Solution: Instead of touching the vector database, we stored ingested documents in a version-controlled system. This allowed us to build query filters for embeddings at runtime, reducing search space and ensuring secure, fine-grained access control.
4. Bonus Approach: One collection, many tenants
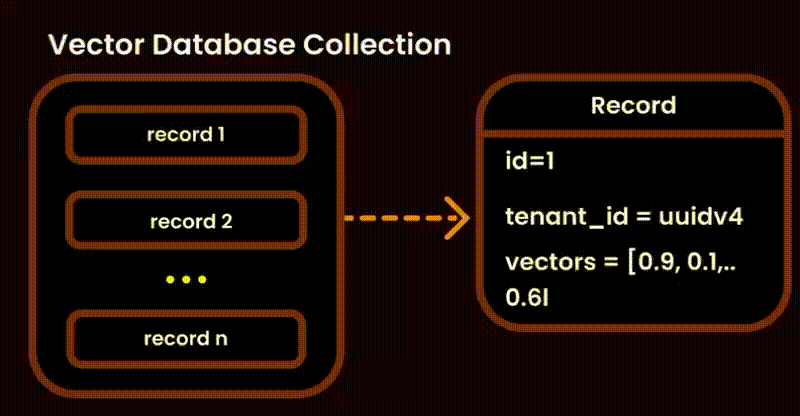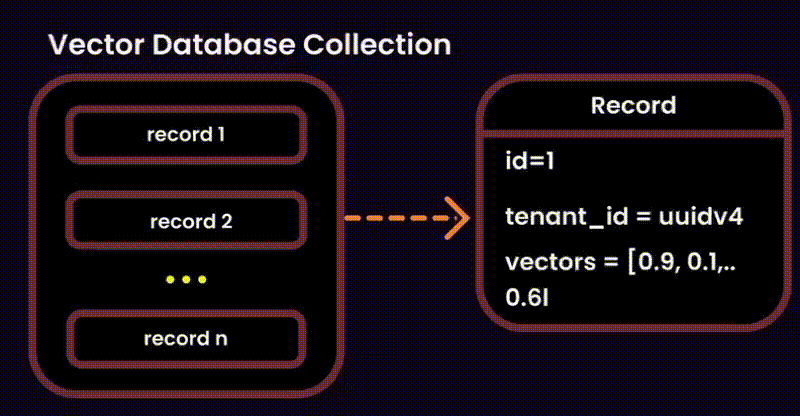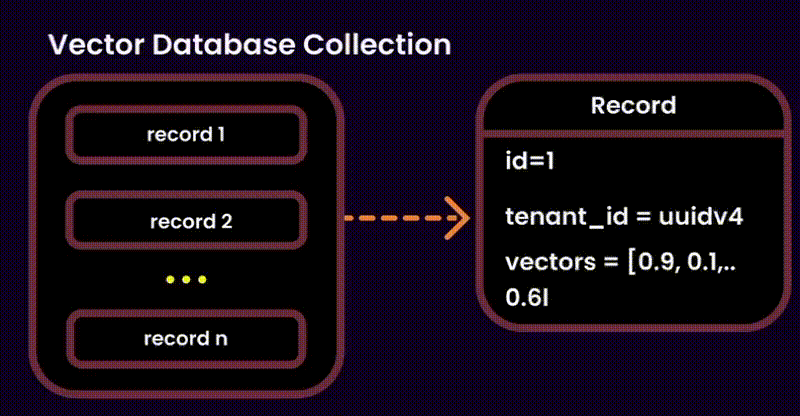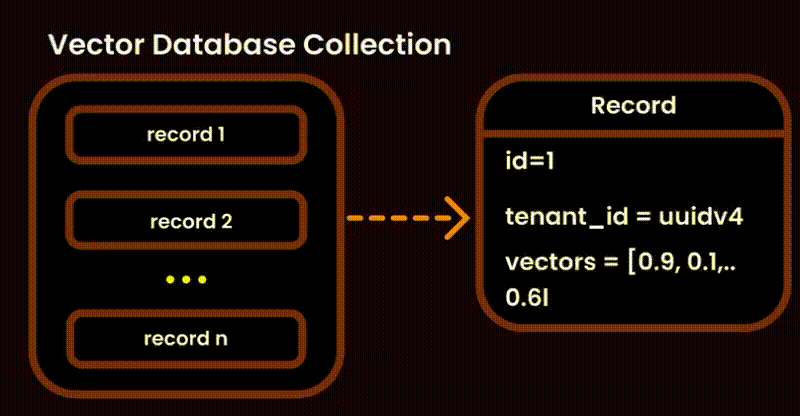
I’ve added this just for the sake of the article. But many of you may find this solution useful.
Think of this as a shared library. All the tenants embeddings are stored under the same collection , with a tenant_id tag to keep chunks organized. While this is an excellent solution for hosting millions of small-medium sized paying tenants, dropping resources costs, ease of maintenance, it comes along with some important disadvantages:
Resource hogging: A few clients may dominate the database through retrieval or indexing process, too many documents chunks, or to many queries resulting into an resource unbalancing.
Low isolation: This is nothing new, tenants can easily gain access to embeddings increasing the risk of unauthorized access, and there is a risk of vector injection attacks.
High-Coupling: Which means low autonomy of tenants, any operation on one tenant can easily break others sharing the same collection.
5. Conclusion
Key takeaways from this exploration include:
• Privacy is paramount: Multitenancy isn’t just about shared resources—it’s about securely isolating data between tenants, especially in a dynamic AI-driven system.
• Trade-offs are inevitable: Every architectural choice comes with its pros and cons. As architects, our role is to choose the solution that best fits the problem at hand while leaving room for future scalability and changes.
• Design for adaptability: Early-stage products, especially in AI, face constant evolution. Anticipating potential pivots, such as on-premise deployments or varying client demands, can save engineering teams significant time and resources in the long run.
• Engineering beyond storage: Generative AI systems don’t just store data; they retrieve, process, and generate knowledge in near real-time. This adds layers of complexity when designing multitenant architectures.
The combination of embedding collection separation, role-based access controls, and a modular approach to database management gives us a solid foundation for the system we’re building. It allows for fine-grained control over data while maintaining scalability and flexibility.
In the next article, I’ll shift from theory to practice. I’ll share the implementation details, including code snippets, design patterns, and practical tips for building similar systems. If you’re an engineer passionate about building scalable and secure AI systems, you don’t want to miss the next part of this series!
Don’t miss the gold mine of articles coming! Subscribe ⬇️