
Uplifted RAG systems: A 4-part deep dive into GraphRAG
Part 1/4: The RAG Challenge: Exposing the Gaps in Modern Retrieval-Augmented Generation


Introduction
Retrieval-Augmented Generation (RAG) has been the go-to for building question-answering and content-generation systems for a while now. The idea sounds simple enough: use a language model to generate answers by pulling info from a database or a set of documents. But when tasks get more complex, traditional RAG systems start to struggle. Sure, they can handle basic questions, but they often fail when it comes to more nuanced or interconnected research needs.
In this first post of our Uplifted RAG Systems series, we’re diving into the common issues with standard RAG setups. Think oversimplified document searches and missing out on multi-hop reasoning. By understanding these gaps, we can start to see why a basic “search and generate” approach just doesn’t cut it anymore—and how new techniques are stepping in to fill those gaps.
🔗 This is a 4-part series. The content is split as such:
Part 1: The RAG Challenge: Exposing the Gaps in Modern Retrieval-Augmented Generation
Part 3: Building the Agentic GraphRAG System—Data Pipeline, Monitoring, and Orchestration
Table of contents:
Linear Document Retrieval
The Context Blindness Challenge
The Multi-Hop Reasoning Gap
The Black Box Problem
Conclusions
1. Linear Document Retrieval
Traditional RAG systems approach document retrieval with a surprisingly simplistic mental model. They essentially say, “Here’s a query, let’s find the most similar documents based on vector similarity.” This linear thinking manifests in code that looks deceptively straightforward:
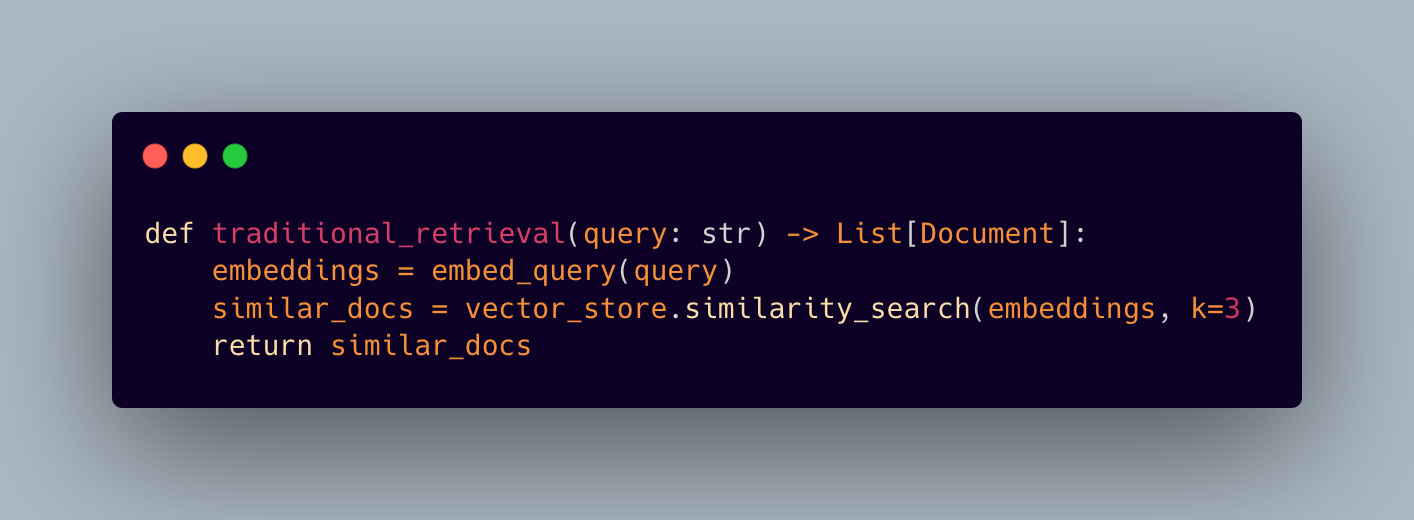
While this approach works for basic question-answering, it falls apart when dealing with academic research where papers are deeply interconnected through citations, shared methodologies, and evolving ideas. Think about how researchers actually work — they don’t just read individual papers in isolation; they follow citation trails, track how ideas evolved over time, and understand papers in the context of their authors’ broader research agendas.
1.1 The Context Blindness Challenge
Perhaps even more problematic is how traditional RAG systems handle context — or rather, how they don’t. Most implementations use a static, one-size-fits-all approach to query processing:
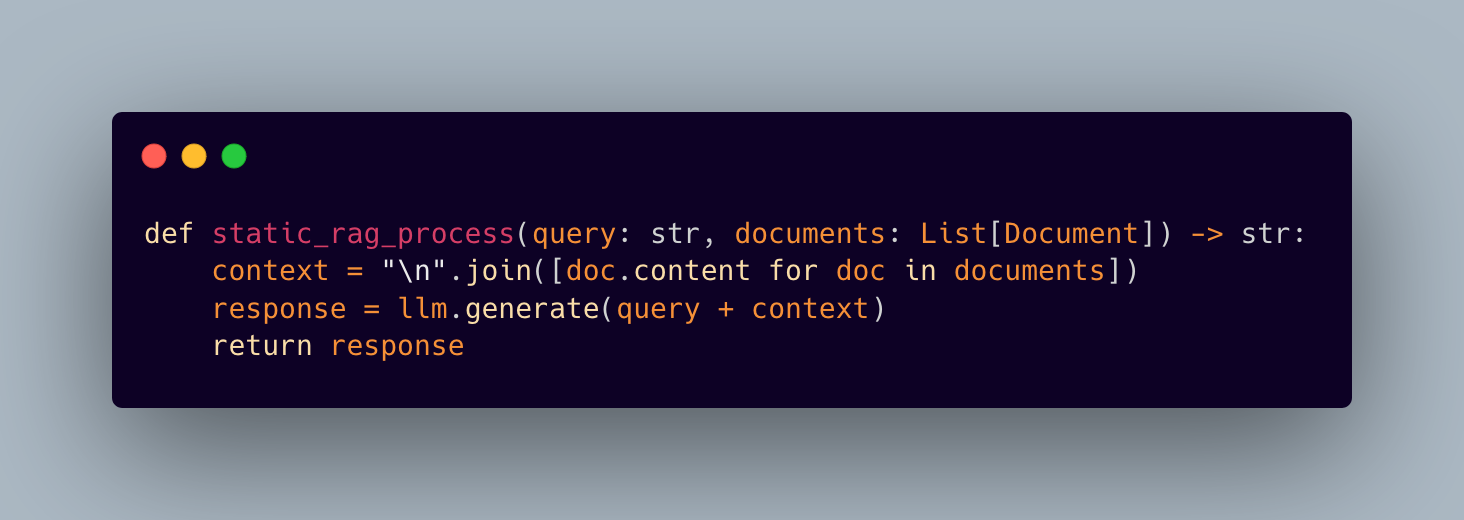
1.2 The Multi-Hop Reasoning Gap
One of the most significant limitations becomes apparent when we need to connect insights across multiple papers or concepts. Traditional RAG systems struggle with what researchers do naturally — following chains of reasoning across multiple documents. Instead of the simplified single-hop retrieval:

We need systems that can traverse the knowledge graph much like a researcher would:
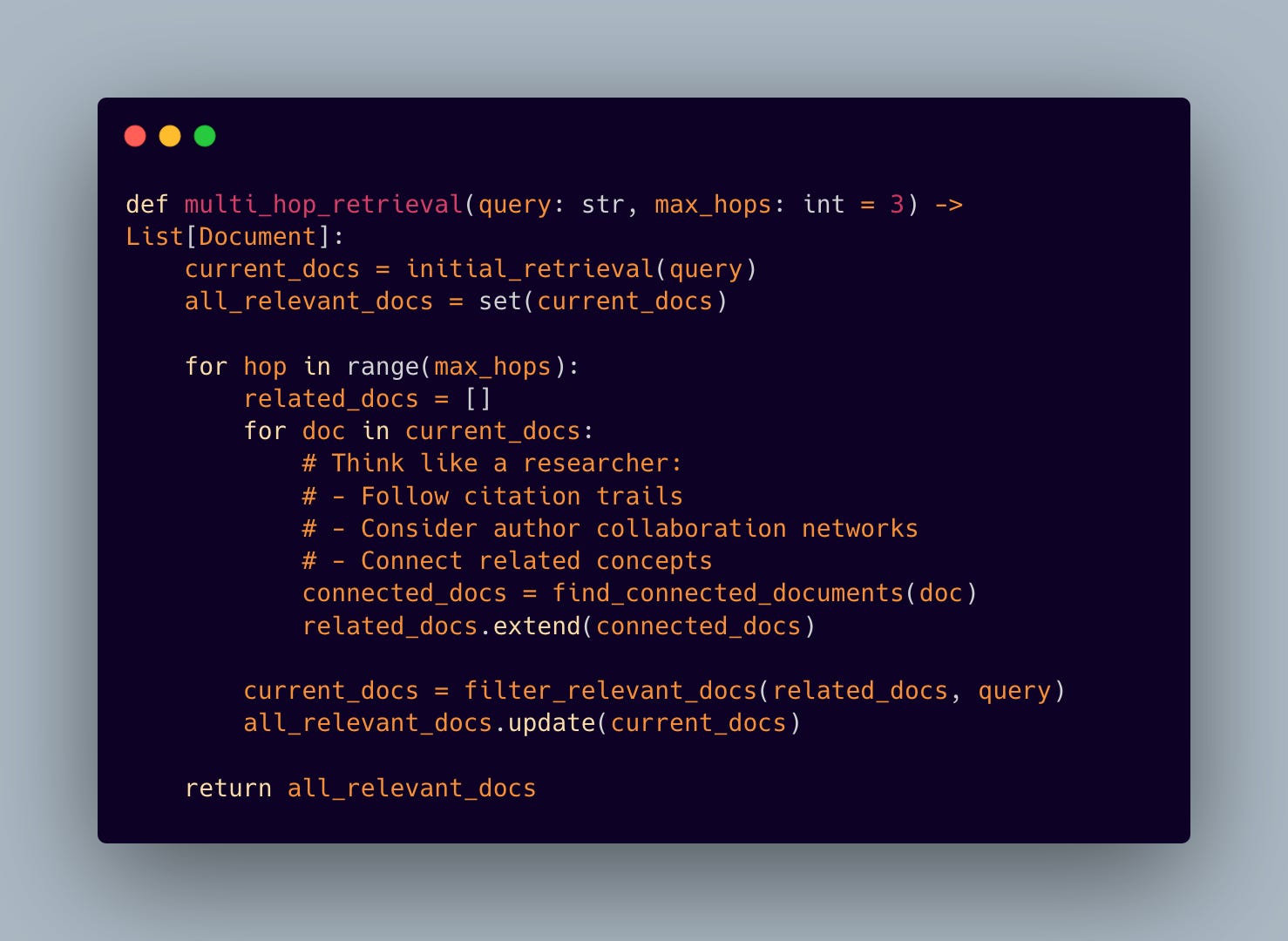
1.3 The Black Box Problem
Perhaps most frustratingly, traditional RAG systems offer limited insight into their performance. They typically track basic metrics like retrieval time and document count. But in a research context, we need to understand much more:
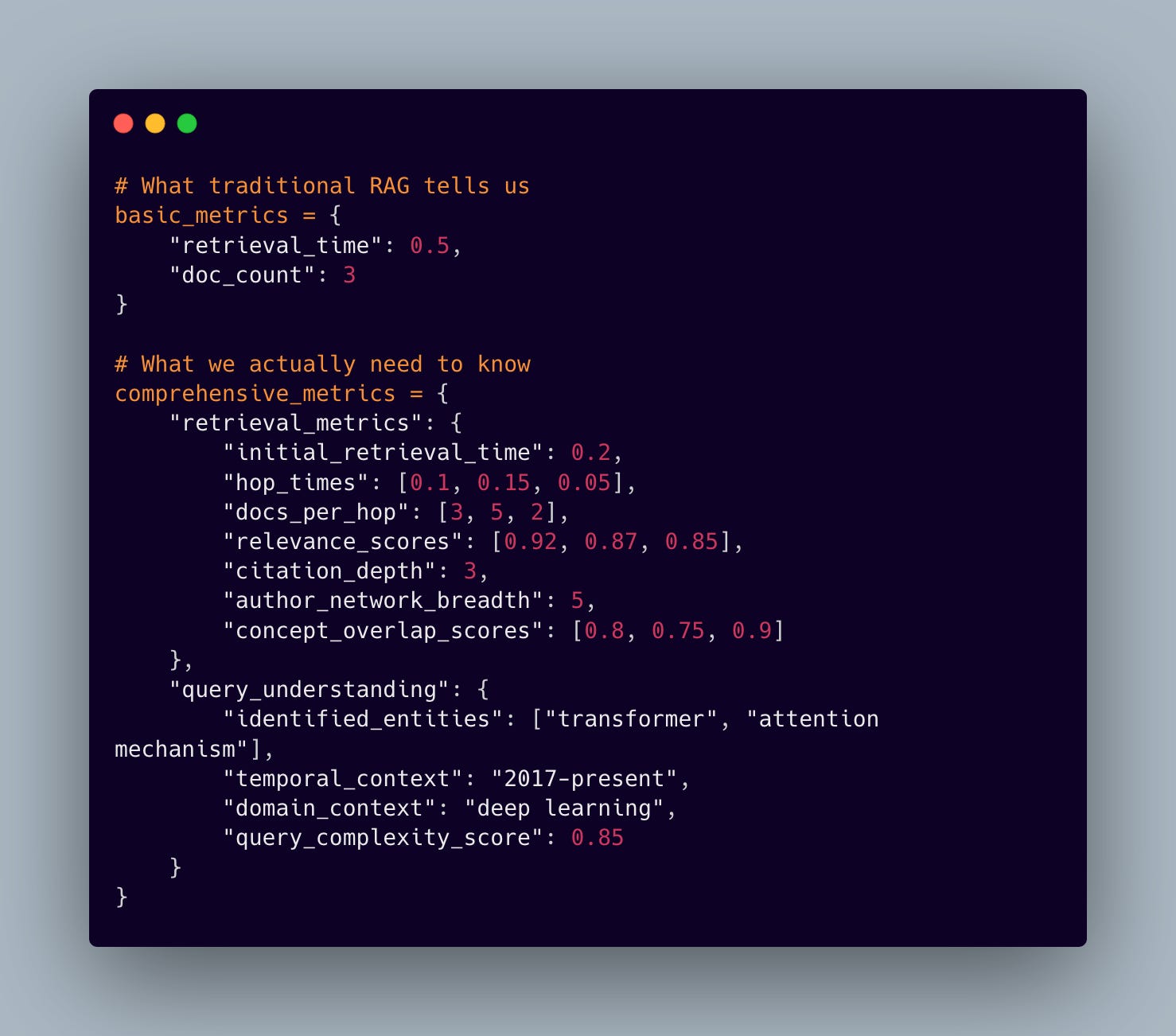
2. Conclusion
Traditional RAG systems have their fair share of issues—narrow retrieval strategies, blind spots in context, and struggles with multi-hop reasoning, to name a few. That’s exactly why we need a fresh approach. One that connects the dots between data, adapts to changing contexts, and gives us a clearer picture of how the system is performing.
This is just the start of our series on Uplifted RAG Systems with CometML Opik. In the next articles, we’ll explore how things like graph-based architectures, agent-driven query processing, and real-time experiment tracking can tackle these challenges head-on. Stay tuned!
🫵🫵🫵
Enjoyed this breakdown of the core RAG challenges?
Make sure you don’t miss the rest of our journey. We’ll explore how graphs and agentic models can revolutionize retrieval, ensuring you’re equipped with the latest advancements in AI-driven knowledge exploration.🔗 Check out the code on GitHub and support us with a ⭐️