Image pipelines: 300 product photos to caption. Progress bar stops at 23%.
The pattern is always the same: your workload works for 10 items. Then a customer sends 100 items, and everything breaks.
I’ve been there. Many times.
This article shows how we fixed it for one client, a sales intelligence platform analyzing 127 deals. But the pattern applies to any GenAI batch workload where:
Each item is independent (item A doesn’t need item B’s result)
Each item takes significant time (5-60 seconds via LLM)
The total workload exceeds Lambda’s 15-minute limit
If that describes your system, keep reading.
Practical case study: Sales Deal Intelligence Extraction
Before I show you any architecture, let me describe what we’re dealing with.
The client’s system analyzes sales deals to extract intelligence signals:
Qualification assessment: BANT criteria (Budget, Authority, Need, Timeline) scored 0-100
Each deal is independent - Deal A’s analysis doesn’t depend on Deal B’s. Perfect for parallelization.
LLM calls are slow - 25-35 seconds per deal. Sequential processing stacks wait times.
Large pipelines - The client’s pipeline had 127 deals. More pipelines had 200+.
Timeout constraints - Lambda’s 15-minute limit becomes a hard ceiling.
Traditional approach: processes are executed sequentially in a single Lambda. Here’s what that looked like:
# Sequential processing (the broken version)
def analyze_deals_sequential(deals):
results = []
for deal in deals: # 127 deals
intelligence = llm_analyze(deal) # 30 seconds each
results.append(intelligence)
return results # Never reached for 127 deals
```
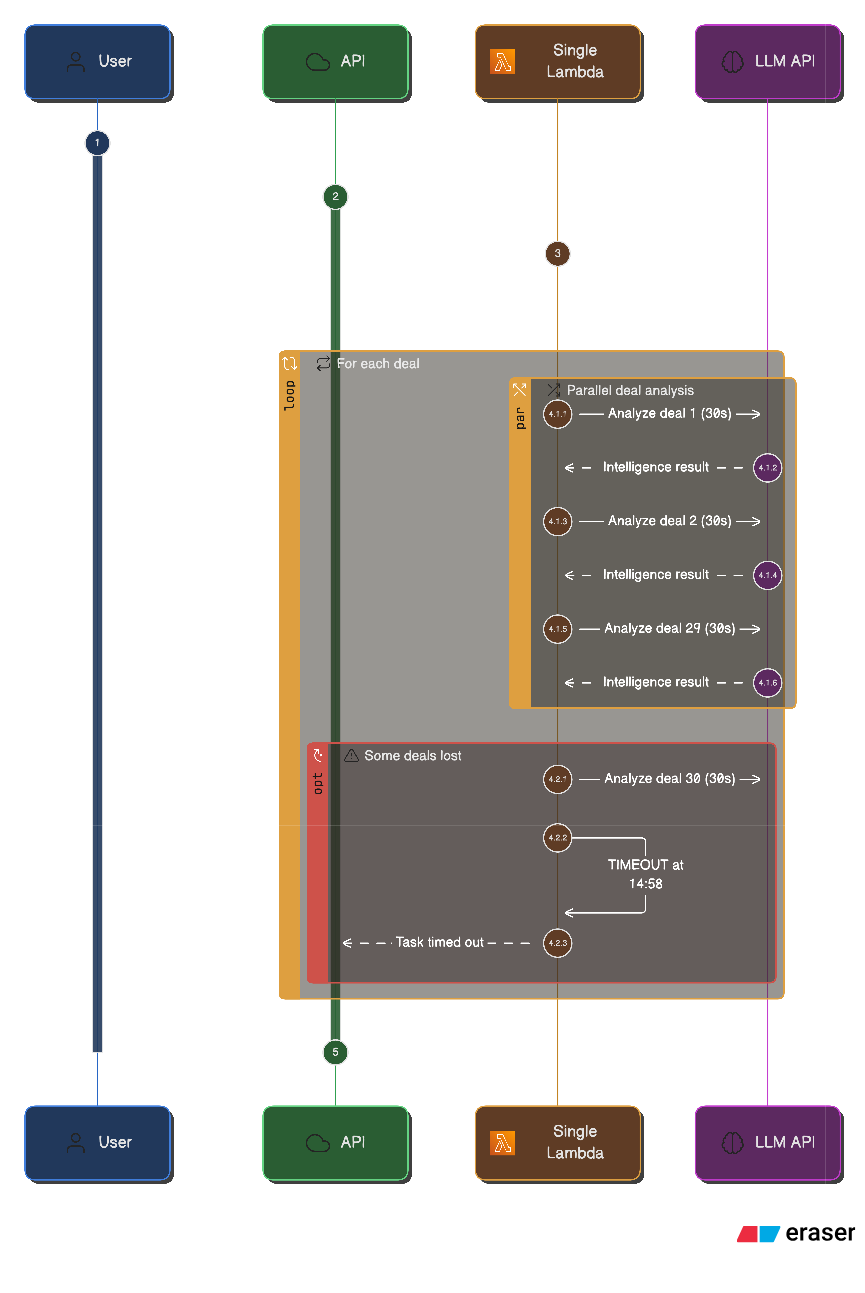
**The problem:** At 14:58, Lambda kills the function. You've processed 29 deals. The remaining 98 deals? Lost. No way to resume. The user sees "Task failed" with no explanation.
Here's what the CloudWatch logs showed:
```
[14:52:33] Processing deal 29/127: "Enterprise Renewal - Q4"
[14:52:58] Deal 29 analysis complete
[14:52:58] Processing deal 30/127: "New Logo - Manufacturing"
[14:58:00] Task timed out after 900.00 seconds
That’s it. No error. No partial results saved. Just... timeout.
Keep reading this, and you will to build this:
Fan-out pattern for GenAI systems
The Before: Sequential Processing
Here’s what the broken architecture looked like:
The problem: One Lambda, one deal at a time, 15-minute limit. 29 deals processed, 98 lost. No checkpoint was implemented, so all the progress was lost.
Decision 1: The Orchestrator Problem
The first architectural decision: who coordinates the work?
Lambda can’t orchestrate itself. If you try to invoke 50 Lambdas from within a Lambda, you hit the same timeout. You need something that can wait.
The naive approach: Use Step Functions.
Problem: Step Functions have their own limits, and they’re expensive for this use case. You’re paying for state transitions, not compute.
The better approach: ECS (Elastic Container Service).
ECS runs Docker containers with no timeout limits. It can:
Split work into batches
Invoke Lambdas in parallel
Wait for completion (polling Redis)
Collect results
Continue with the next phase
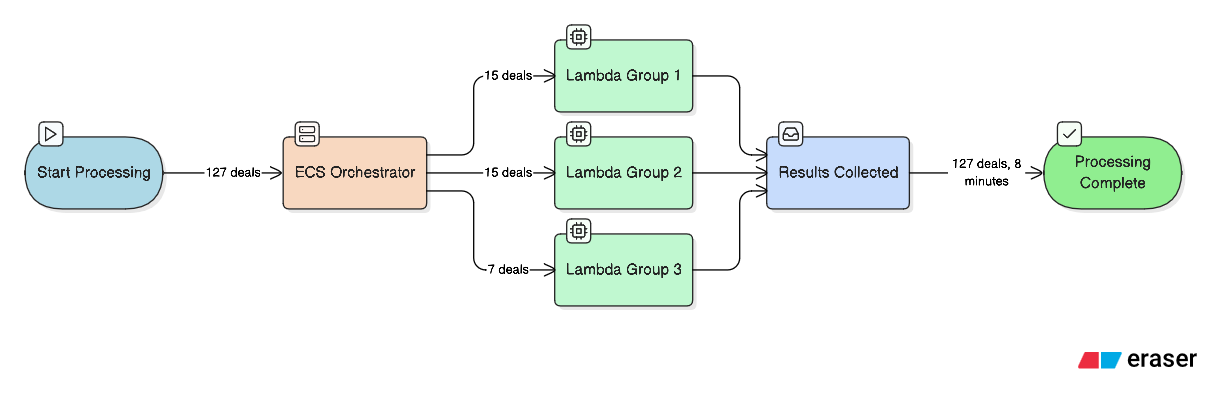
The After: Fan-Out Pattern
Here’s what the fixed architecture looks like:
The solution: ECS orchestrates, 9 Lambdas process in parallel, each batch completes in ~7 minutes (well under 15-minute limit). All 127 deals processed successfully.
Why ECS and not just more Lambdas? Because someone needs to wait. ECS can poll for 40 minutes if needed. Lambda dies at 15 minutes.
Why not just ECS for everything? Because 9 ECS containers processing deals costs more than 9 Lambda invocations. Lambda is cheaper for the actual work. ECS is the patient coordinator.
But where do the batches come from? And how do we get data to each Lambda
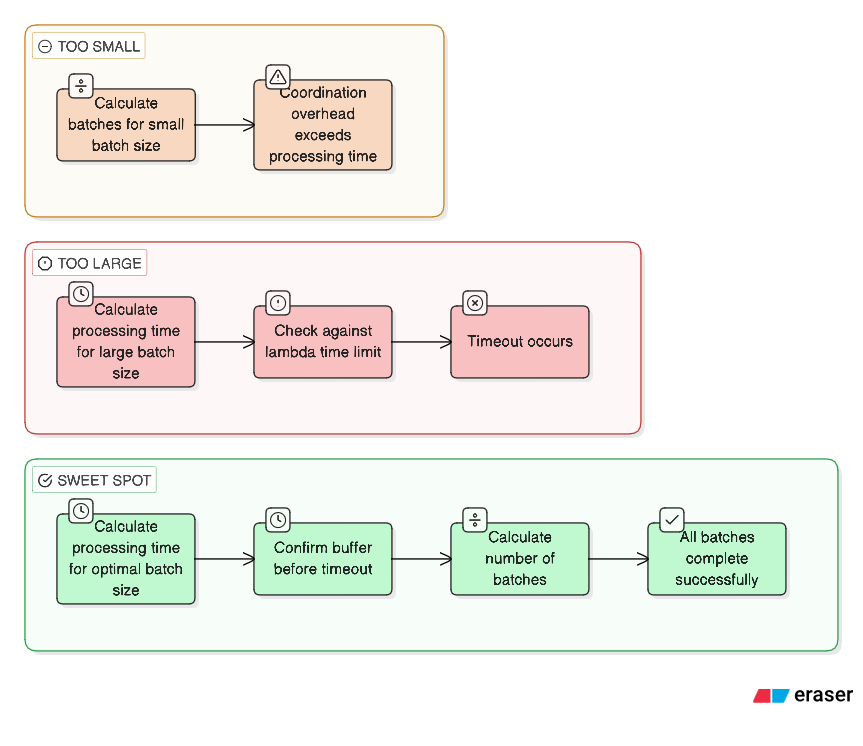
Decision 2: The Batch Size Problem
How many deals per Lambda batch?
Too small (5 deals per batch): 127 deals = 26 batches. Overhead of coordination exceeds processing time. You’re spending more time splitting and collecting than processing.
Too large (50 deals per batch): 50 deals × 30 seconds = 25 minutes. Lambda timeout is 15 minutes. The batch dies.
127 deals ÷ 15 = 9 batches (8 full batches + 1 with 7 deals)
But here’s what we learned the hard way: not all deals take 30 seconds.
Some deals have 200 emails, 50 notes, 15 calls. Those take 45-60 seconds. A batch of 15 “heavy” deals can still timeout.
The solution: Dynamic batch sizing based on content volume. But that’s complex. We started with 15 and monitored. For the client’s pipeline, it worked.
Now we have 9 batches. But how do we get 15 deals worth of data to each Lambda?
Decision 3: The Payload Problem
Lambda has a 6MB payload limit. Each deal bundle contains:
Deal metadata
All emails (with bodies)
All notes
Call transcripts
Document metadata
127 deals × average bundle size = ~45MB. Way over the limit.
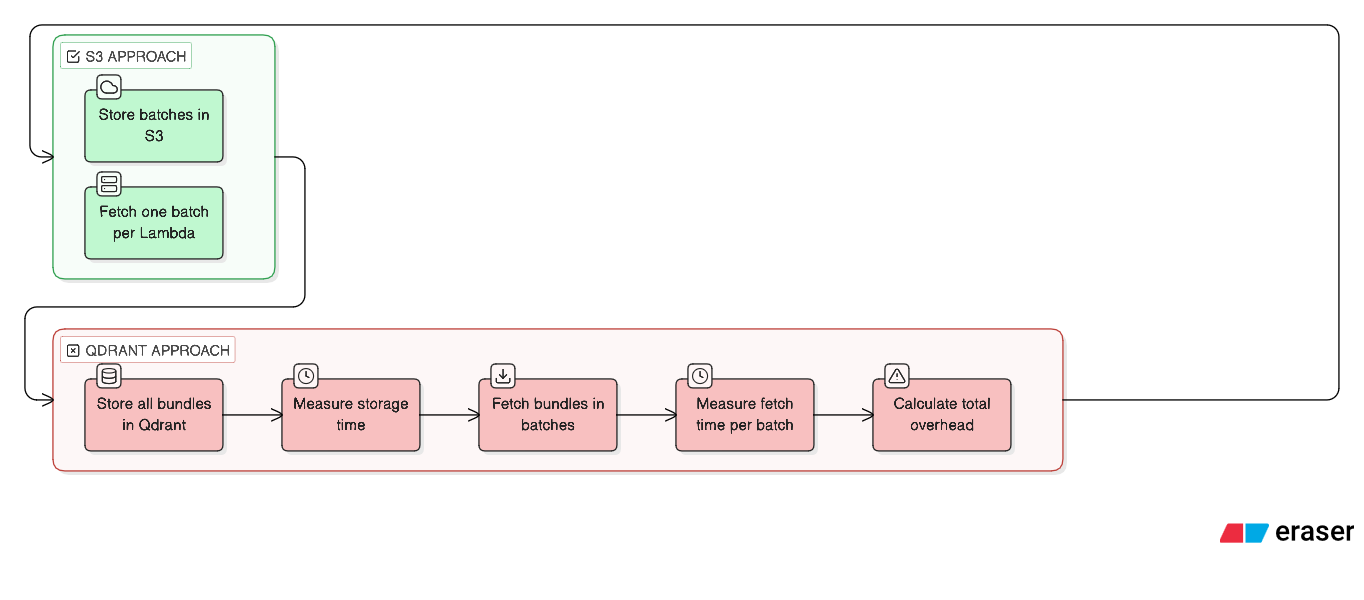
The first attempt: Store everything in Qdrant.
We were already using Qdrant for semantic search. The logic seemed “logic” 😂 : Qdrant stores vectors and payloads, so store the deal bundles as payloads alongside their embeddings. One system, one query, everything in one place.
Here’s what we tried:
# The Qdrant approach (don't do this)
for deal in deals:
bundle = compress_bundle(deal) # gzip compression
qdrant.upsert(
collection="deals",
points=[{
"id": deal.id,
"vector": embed(deal.summary),
"payload": {
"bundle": base64.encode(bundle), # 200KB-2MB per deal
"metadata": deal.metadata
}
}]
)
Three problems emerged immediately.
Problem 1: Qdrant isn’t a blob store. Qdrant is optimized for vector similarity search, not for storing and retrieving large binary payloads. We were using a Ferrari to move furniture. Each upsert with a 500KB payload took 800ms. Multiply by 127 deals, and just the storage phase took 100+ seconds.
Problem 2: Compression didn’t provide enough relief. Deal bundles with email bodies and call transcripts compress to 40-60% of the original size. A 1MB bundle becomes 500KB. Still too large for efficient Qdrant payloads. t.
First attempt (gzip): 50% reduction, still 63.5MB total, too large
Second attempt (brotli level 11): 15% better compression, but processing time increased by 40%. Brotli level 11 is the highest compression setting (0-11), offering the smallest file sizes (best compression ratio) but requiring the most time and CPU to compress data;
Problem 3: Retrieval was worse. When Lambda needed to fetch a batch of 15 deals, Qdrant had to deserialize 15 large payloads from its storage engine. A batch fetch that should take 50ms took 3-4 seconds. Multiply by 9 batches, and we’d added 30+ seconds of overhead just to retrieve data we’d already processed.
100 seconds to store. 3+ seconds per batch to retrieve. We’d added two minutes of overhead before any actual work happened.
The solution: S3 bucket.
def store_batch(
self,
job_id: str,
batch_index: int,
bundles: List[Dict[str, Any]],
) -> bool:
"""Store a batch of bundles to S3 as gzip-compressed JSON."""
s3_key = f"audit_bundles/{job_id}/batch-{batch_index:04d}.json.gz"
# Serialize to JSON
json_data = json.dumps(bundles, default=str)
# Compress with gzip
buffer = BytesIO()
with gzip.GzipFile(fileobj=buffer, mode="wb") as gz:
gz.write(json_data.encode("utf-8"))
compressed_data = buffer.getvalue()
compressed_size_mb = len(compressed_data) / (1024 * 1024)
# Upload to S3
self.s3_client.put_object(
Bucket=self.bucket_name,
Key=s3_key,
Body=compressed_data,
ContentType="application/gzip",
ContentEncoding="gzip",
)
logger.info(
f"Stored batch {batch_index} for job {job_id}: "
f"{len(bundles)} bundles, {compressed_size_mb:.2f} MB compressed"
)
return True
S3 is designed for blob storage. It handles large objects efficiently. It’s cheap. It’s fast for sequential reads.
ECS Worker:
1. Split 127 deals into 9 batches
2. Store each batch in S3 as gzip-compressed JSON
s3://bucket/audit_bundles/job-123/batch-0000.json.gz
s3://bucket/audit_bundles/job-123/batch-0001.json.gz
...
3. Invoke Lambda with: { job_id: "job-123", batch_index: 0 }
Lambda:
1. Receives job_id and batch_index
2. Fetches batch from S3: s3://bucket/audit_bundles/job-123/batch-0000.json.gz
3. Decompresses and processes 15 deals
4. Stores results in Redis
The same 127 deals: S3 upload took 8 seconds. Batch retrieval took 200-400ms each. Total overhead dropped from 130+ seconds to under 15 seconds.
Each Lambda only fetches what it needs. No payload limit issues. S3 is cheap storage for temporary data. And Qdrant goes back to doing what it’s good at: vector search.
Now we have 9 Lambdas running in parallel. But when 9 Lambdas finish at different times, how do we know when ALL are done?
Decision 4: The Coordination Problem
The naive approach: Poll a database. ECS checks every 5 seconds: “Are all batches complete?”
Here’s what breaks:
Lambda 0 finishes at 14:23:45.123
Lambda 1 finishes at 14:23:45.127
Lambda 2 finishes at 14:23:45.131
ECS polls at 14:23:45.000 → "3/9 complete"
ECS polls at 14:23:50.000 → "3/9 complete" (missed the updates)
ECS polls at 14:23:55.000 → "6/9 complete" (missed more)
Race conditions. Missed updates. ECS might think only 6 are done when all 9 finished.
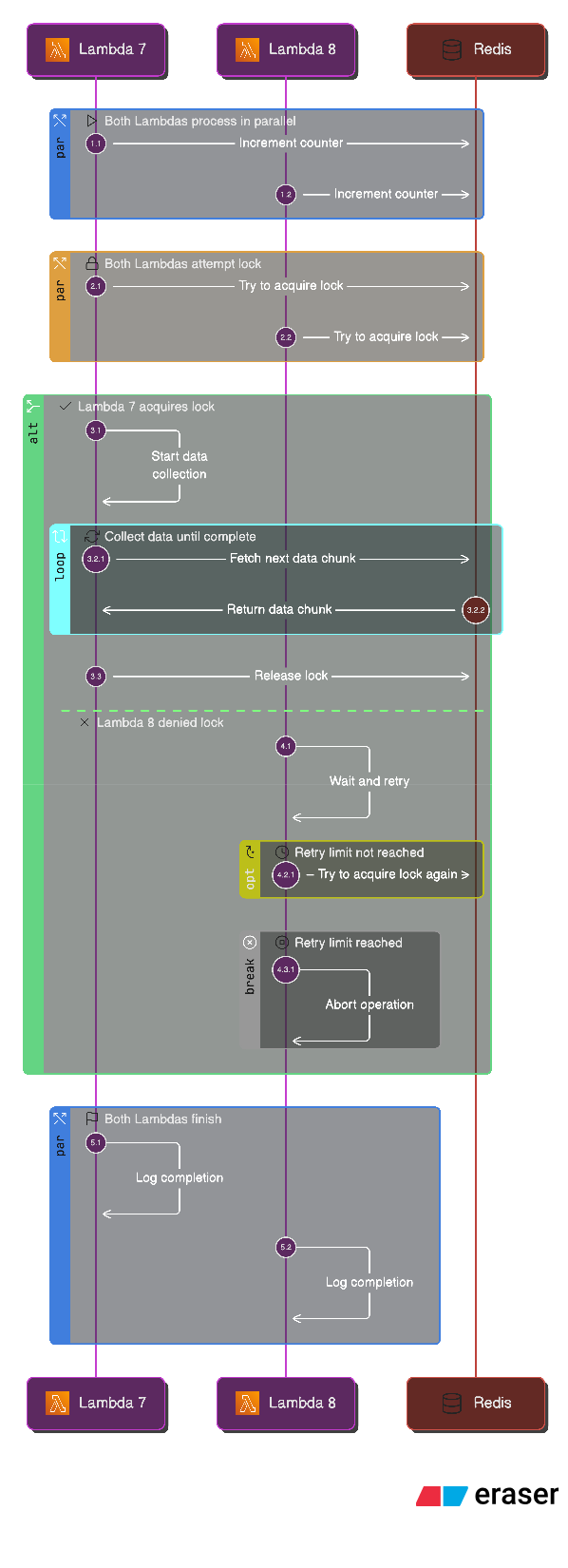
The better approach: Atomic counters in Redis.
When a Lambda finishes:
# Lambda stores results
redis_client.rpush(f"results:{job_id}", json.dumps(batch_results))
# Atomic increment
completed = redis_client.incr(f"job:{job_id}:completed")
# Redis guarantees INCR is atomic - no race conditions
# Check if this is the last batch
if completed == total_batches:
# Try to acquire collection lock (atomic)
lock_acquired = redis_client.setnx(f"job:{job_id}:collection_lock", "1")
if lock_acquired:
# This Lambda triggers collection
trigger_collection_phase()
Why atomic operations matter: Two Lambdas that finish at the same millisecond increment the counter. Redis guarantees the counter is accurate. Only ONE Lambda acquires the collection lock (SETNX is atomic). No race conditions, no duplicate work.
This map is then used for the next phase: smart clustering. Deals with similar risk signals get grouped together. Deals with high qualification scores get prioritized.
But here’s the problem: what if a batch fails?
Decision 6: The Failure Handling Problem
Lambda batch 3 fails. 15 deals lost. What happens?
The naive approach: Fail the entire job. Problem: You’ve processed 112 deals successfully. Throwing away all that work because 15 failed is wasteful.
The better approach: Track failures, continue with partial results.
Here’s what the Redis state looks like when batch 3 fails:
The job completes with 115 successful extractions out of 127 deals. The clustering phase continues with partial data. The user sees a warning: “115/127 deals analyzed successfully. 12 deals failed due to timeout.”
But here’s what we learned: Some failures are transient. A Lambda timeout might be due to a slow LLM API response. Retrying that batch might work.
The solution: Automatic retry for failed batches. But that’s a future improvement. For now, we fail gracefully and continue.
What about the orchestrator itself? How long should ECS wait?
Decision 7: The Timeout Calculation Problem
How long should ECS wait before giving up?
The naive approach: Fixed timeout. “Wait 30 minutes, then fail.”
Problem: 127 deals might take 8 minutes. 500 deals might take 25 minutes. A fixed timeout either wastes time (waiting 30 minutes for an 8-minute job) or fails prematurely (500 deals need more than 30 minutes).
The better approach: Dynamic timeout based on deal count.
Redis coordination - Atomic counters track completion, no race conditions
Graceful failure handling - Partial results continue, failures are tracked
Dynamic timeouts - Wait time scales with workload size
The result: 127 deals processed in 8 minutes instead of 63.5 minutes. No timeouts. No lost work.
When This Pattern Breaks
Don’t use fan-out when tasks depend on each other, if deal B’s analysis needs deal A’s result, you can’t parallelize. Small workloads don’t benefit either; 10 deals should be processed sequentially because the coordination overhead exceeds the processing time. If results must be in strict order, parallelization breaks that since batches complete at different times. And if a single LLM call can handle everything, there’s no need to split.
Use fan-out when processingmany independent items (the more items, the bigger the win), when each item takes significant time (30 seconds per deal makes parallelization obvious), when wall-clock time matters to users, and when workloads are bursty (Lambda’s auto-scaling handles spikes better than fixed infrastructure).
If this article helped you think differently about scaling GenAI workloads, share it with someone building distributed systems. And if you want to discuss your own timeout challenges, I'm always up for a conversation, sometimes the best insights come from seeing how these principles apply to problems I haven't encountered yet.



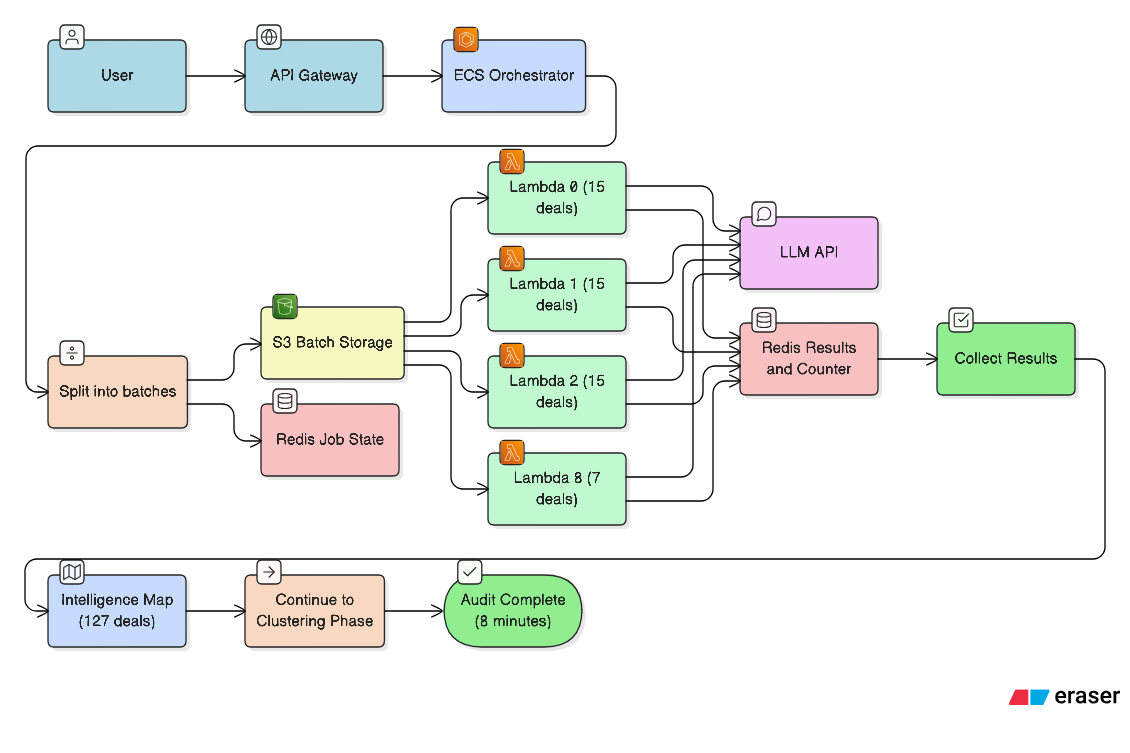
The orchestrator is a challenge but ECS over step functions? Is that so the code can run locally?