
Multi-source ingestion pipelines should be easier
Building a scalable ingestion pipeline to extract data from multiple sources the right way

Key takeaways (if you have ADHD and can’t read the whole thing)
Sometimes, using libraries is
wackmaking the system more complicated than it needs to be.By spending some extra time and effort at the beginning of a project, building something custom can save lots of time in the future,
Ray is easy to use and super useful when it comes to parallelization.
This is the era where Data is King. But you already knew that. A simple RAG system is just a concept, while it’s actual usefulness comes from understanding and ingesting large amounts of data, from wherever the user stores it. In bigger companies, that means JIRA boards and documentations, personal Google Drives / Sharepoints and internal documents. You get the gist of it.
So if you’re the dev tasked with bulding this advanced RAG System or a Knowledge Graph (or something else but related), you have 2 options:
Use an already-existing framework like LlamaIndex which is still lacking in production adaptability;
Or gain some control by building a framework yourself

If you choose the red pill, this article is a comprehensive guide on HOW to actually do that.
Table of contents
Using the right patterns
Building a pipeline
Connectors
Putting it all together
Scaling with Ray
Conclusion
1. Using the right patterns

Not too long ago, I worked on a project that inspired this article. My task was implementing a scalable ingestion system cable of taking data from common platforms where users store data. Think Google Drive, Notion and the likes.
The catch? The list of data sources (or connectors) was projected to include all the major platforms and prioritizing which ones to do first was a mess. So, at any point, a new connector might be requested, unplanned, and this raised a few problems.
It meant that we could not necessarily use a library like LlamaIndex because it did not have implementations for all of the data sources initially planned. Imagine just how messy a half-LlamaIndex half-custom implementation would be at 10s of connectors.
The only smart option left was doing things from the ground up and embrace custom implementations.
An abstract setup
Let me pose you with a challenge. How would you implement a scalable system where each new data source added would not change the whole system? Abstraction.
What want to emphasize here is that when you are dealing with an ingestion system that is always expanding and the codebase is growing at a fast rate, structure is more important than functionality. So even if, at first glance, doing all of this seems like over-engineering, trust me, in the long run, it will end up saving you precious time.
Through this article, you will see that many choices that the team and I made on the solution are specifically designed to make this system as modular as possible and easy to extend in the future.
Our salvation comes in the form of good old engineering and we returned to two patterns that proved to be the perfect fit:
Pipes and filter pattern - this helps us create a generic structure when building pipelines by leveraging the concept of filters.
Think of the filters as a chain of black boxes that are connected (in this case, inside the pipeline) and each box receives an input, does some processing on said input and passes the output to the next box. The process repeats itself until the chained is finished.
In this implementation, we will use “steps” instead of “boxes” but the concept stays the same.Builder pattern - this helps us construct complex objects, step by step. We took some aspects from it that fit the use case better.
We prepared for a future where each connector may end up having its own pipeline with a different sequence of steps and logic. So we used builder objects to hold all the logic and dependencies that which are to be injected.
2. Building a pipeline
Just like building a house, the foundation needs to be strong. Naturally, we first cover the base classes. We’re bulidng a Lego house, meaning that each of the base classes can be looked at as Lego bricks that build one version of one house. This makes it so easy to adjust later with adding/removing blocks as needed.
These components are designed to solve the problem of implementing an ever-evolving ingestion system while also keeping the codebase easy to extend and maintain (like somebody who considers Clean Code as some sort of bible).
There are 3 base components to the ingestion system:
Pipeline Step (Filters)
With the power of magic methods in Python, we create a base abstract step that can be run using the __call__. Since each step will be different, this will ensure that all the steps will be run the same and we can pass whatever arguments we want to them.

Base Pipeline
This is the pipeline object that will be created from the builder class. It has two methods: run(), where each step inside the pipeline is called, and the result of the step logic is returned to the next one; and add_step(), a method for appending a step to the steps list.

Pipeline Builder
This is the base builder class that acts as an interface. If someone later comes and implements a new pipeline, we can ensure that all pipelines will have to use the build() method to enforce consistency across our system.

3. Connectors
A connector in this system can be looked at as an entry point for the data, and in most cases, this will represent a third-party API. As an example, in this article, we will implement a connector for Atlassian so we can ingest epics/stories/tasks from Jira. For this implementation, a connector will have two parts: Gateway and Reader.
Gateway
The JiraClient class acts as a gateway that allows seamless integration with the Jira REST API using OAuth authentication. This transition from basic authentication to OAuth is needed for security purposes, allowing us to interact with Jira without exposing sensitive API tokens via code.
Setting Up OAuth in Atlassian
Before using the JiraClient, you must create an OAuth 2.0 app in Atlassian Developer Console:
1. Go to Atlassian Developer Console and create a new app.
2. Create an OAuth 2.0 Integration:
• Select OAuth 2.0 (3LO) authentication;
• Register your app by providing a name and selecting Jira API as the scope;
• Add the required scopes:
read:jira-work (to read Jira issues)
read:jira-user (to access user information)3. Set the Callback URL:
• The redirect URI must match what you define in settings.ATLASSIAN_REDIRECT_URI (e.g., http://localhost:8080/callback);
• Jira will send an authorization code to this callback URL after user authentication.
4. Retrieve Your Client ID & Secret:
• After registering your app, copy the Client ID and Client Secret;
• Store them securely and add them to your configuration settings.

Reader
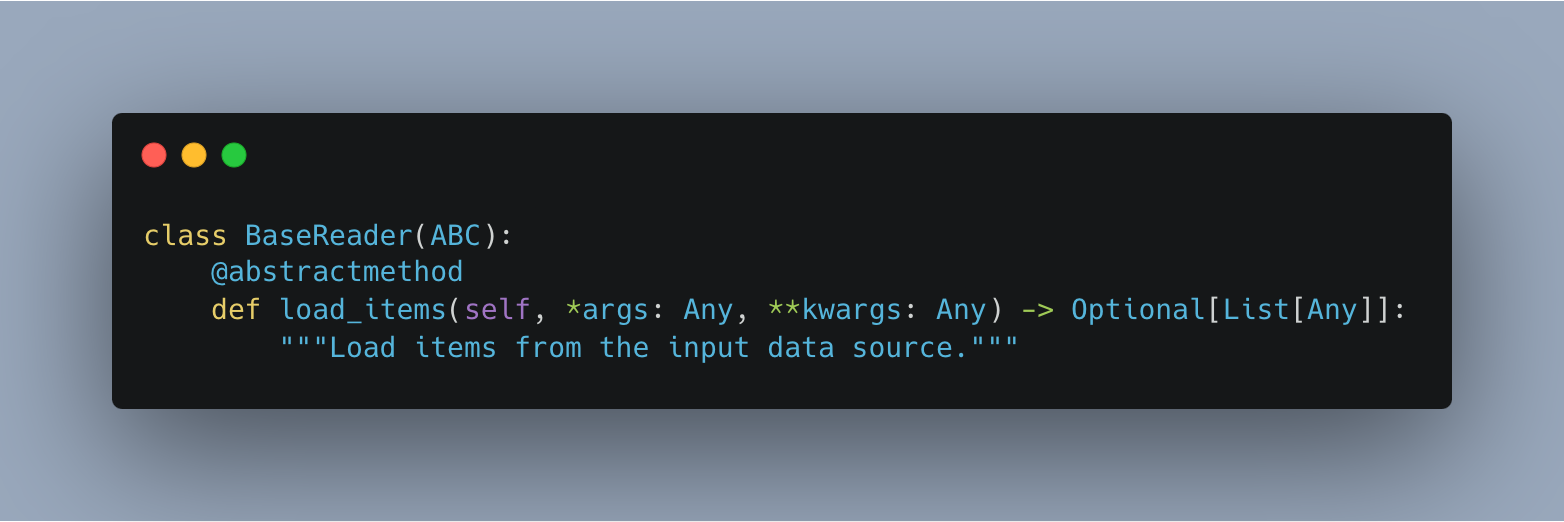
For the reader class we will also implement a BaseReader class that will serve as an interface. Later this will allow us to add more readers to the system and we want all readers to have the load_items() method because when build the steps we want to know which method to use inside the step.
Also, the JiraReader class will encapsulate all the logic necessary for things like formatting the issue metadata, getting the task path, extracting epics as well as the load_items() method that will extract all the issues from a given workspace.

4. Putting it all together
It’s time for buidling that Lego house. First, we create LoadItemsStep which will use the reader’s load_items() method to get all the Jira issues from all the projects.

To build the pipeline we add the step above. It should look like this:

It is also useful to create a Manger/Dispatcher class that will help us register new sources with its intended builders then later use the create_pipeline() method to get a list of all the pipelines that need to be executed.

5. Scaling with Ray
Scaling is a top priority when it comes to ingestion systems. You may have to serve 10 users each with 2 sources: Google and Microsoft, and each sources will have 2 connectors so you end up with 40 pipelines to run.
Doing things sequentially affects the latency and wait time for the user.
But every problem has a solution! And in this case the solution comes in the form of Ray.
The Ray library is a distributed computing framework designed to scale Python applications effortlessly, particularly for workloads involving parallel or distributed execution. In the context of scaling ingestion pipelines, Ray’s remote functions enable parallel execution of tasks, allowing for efficient use of system resources and improved throughput for high-volume data ingestion.
This scaling can be done on multiple levels. From top to bottom, we can scale each pipeline per user/per connection source / per connector/per batch of data.
As you can see, there are many options, and if you have the resources, you can even go crazy and do all of them at once. In this example, we will look at per-connector scaling.
We have a connection source, in this case, Atlassian, and we want to ingest from two different connectors, Jira and Confluence. Then we will have a worker running the pipeline task for each connector.
To scale the pipelines we need a task method that will be annotated with ray.remote() to run it using .remote(), meaning that ray will parallelize the task and aggregate the result for each connector.

6. Conclusion
I hope that by reading this article, you feel emboldened to take this implementation and expand it to fit your own ingestion system and needs. Through this article, you’ve seen how structured engineering choices can turn a constantly chainging system into something modular, scalable, and adaptable.
In a rapidly changing landscape where new data sources and requirements emerge unpredictably, the ability to build a flexible ingestion pipeline is not just a convenience—it’s a necessity. By prioritizing patterns that promote extensibility, using modular connectors, and leveraging parallelization with tools like Ray, we ensure that our system remains robust and future-proof rather than becoming a patchwork of quick fixes.
That being said, engineering is about balance. Sometimes, the best decision is to take the short path by levraging existing frameworks, libraries, and tools to save time and effort. Other times, the best approach is to build from the ground up, ensuring that you have complete control over the system’s architecture. The key is knowing when to optimize for flexibility and when to prioritize speed.
Ultimately, experience will teach you when to build from scratch and when to stand on the shoulders of giants. The most valuable skill you can develop is the ability to make that decision wisely. Whether you take the blue pill or the red pill, the goal remains the same: to build a system that works, scales, and evolves with your needs.
Hey,
Thanks for the awesome article!
The repo is not found, I guess it's private?
Sorry but the link to the full repo doesn't work.