


Monitoring Is Boring
Boosting client satisfaction with smarter AI production systems

🚨 Alert. This article is dangerously practical—no AI buzzword bingo here. Oh, and did I mention? We have CODE. 🧑💻
Oh, and one more thing… we’re now on 🔗 LinkedIn! Follow for snippets of knowledge.
Key takeaways
Observability in AI systems helps track performance and debug issues.
Old-school software principles like modularity and logging are still valuable.
Langfuse offers structured monitoring for LLM interactions.
Observability prevents chaos and improves system reliability.
Nowadays, everything is hyped. You open your LinkedIn account and see 294129124 AI influencers posting something about the latest model or research paper. You go on Google and see the same thing. Everything is on trend.
But like me, you are an AI engineer, and your brain must solve real production problems.
Let’s take this scenario: You are working in a tech startup. You developed a cutting-edge system for four months with multiple AI components (not only GenAI components 😂). The big day has come, and the system has been deployed to the clients. The first feedback came after only 1 day, and is something like this:
CEO: Heeeey Alex, client X said that the output from the summary component is not aligned with the PDF complexity. Oh yes, and also that the extractor is too slow. Oh yes, and the output is too stochastic. Can you see what’s happening and solve yesterday?
Alex: Of course. No. We don’t have observability and monitoring. Do you know the epic and stories from Jira related to that? You didn’t want to prioritize them…
And here we are. In this article, we will discuss why simple principles and foundation engineering can save you weeks of development and help you make your clients happy.
Table of contents
What is observability and monitoring in AI systems? How simple things can destroy an entire system
The complexities of LLM deployment
Tackling non-deterministic outputs
How simple things can destroy an entire system?
Old school software engineering. Please, save me
Bringing structure to chaos
Langfuse → my choice for AI production system
Conclusions
1. What is observability and monitoring in AI systems? How simple things can destroy an entire system
As LLMs keep shaking up the AI and software development world, it is essential to understand how they behave and perform.
That’s where LLM observability and monitoring step in. Observability is all about monitoring an LLM app’s internal state through its outputs, giving developers the insights they need to keep things running smoothly and efficiently.
But first of all, why do we need observability?
The complexities of LLM deployment
Deploying LLMs isn't just plug-and-play. It comes with a unique set of challenges you don't typically see in traditional software development.
Many high-value LLM apps rely on complex, repeated, or even agentic calls to a foundation model, leading to a tangled control flow.
Debugging can quickly become a wild goose chase, making it tough to pinpoint the root cause of issues. That’s where observability really matters.
Tackling non-deterministic outputs
One of the biggest headaches with LLMs is their unpredictability. Unlike traditional software, where outputs are either right or wrong, LLMs generate outputs that can vary every time. This makes it hard to create a consistent quality standard. Developers need smart strategies to evaluate and monitor LLM output quality, especially when models evolve beyond their control. This is where LLM analytics become critical.
How simple things can destroy an entire system?
Consider a RAG system: query decomposition, user intent classification, or document classification. On top of these operations, we can have multiple chains of thoughts for different stages. These are basically calls to an external LLM with a complex prompt behind them. Treating each component independently is pretty simple, but what happens when you chain them and give them to 100+ people to test an entire flow?
Multiple points of failure. The nightmare of any AI system.
This is where observability and traceability come into play. By implementing advanced techniques for monitoring and analyzing LLM systems, developers can gain deep insights into their applications, identify bottlenecks, and continuously improve their performance.
As LLM systems get more complex, the chances of things going wrong multiply, affecting quality, cost, and speed. Without strong observability in place, spotting and fixing these issues becomes a guessing game.
With a solid observability setup, developers get real-time insights into their LLM apps' performance. They can identify latency bottlenecks, dig into the root causes of errors, and fine-tune their systems using real, actionable data.
Imagine this flow:

Each point of this flow can become a point of failure. And don’t forget that this flow is a synchronous process, no agentic stuff. How do we really know what happens at each point? The response can be simple logging. But we want something more structured. We want to understand how the user interacted with the system, what was the model output, parameter, prompt and the list can continue.
2. Old School Software Engineering. Please, Save Me
Alright, let's take a step back. Remember when software engineering was all about modularity, testing, and logging? Yeah, those were the days. The thing is, these principles aren't outdated, they're essential. The magic of traditional software engineering lies in its structure and predictability. You knew where your code might break, and you had systems in place to catch and handle errors.
With AI systems, especially those with LLMs, we need to bring some of that old-school discipline back.
Observability and monitoring aren't just nice-to-haves; they're the difference between a successful deployment and a chaotic fire drill.
Bringing structure to chaos
The problem with modern AI systems is that they often resemble a tangled web of interdependent components. You've got multiple LLM calls, data preprocessing, output validation, and even user interaction layers, all running asynchronously. Without structure, any failure becomes a nightmare to debug.
What if we applied the principles of modularity and separation of concerns to AI systems? What if we logged every step with the same discipline as traditional apps? We'd have a system where observability isn't just an afterthought but a core design principle.
3. Langfuse → my choice for AI production system
Let’s imagine the following flow.
A user is uploading a PDF and waiting for the summary.
Pretty simple in the first place, right? But the whole process has several steps:
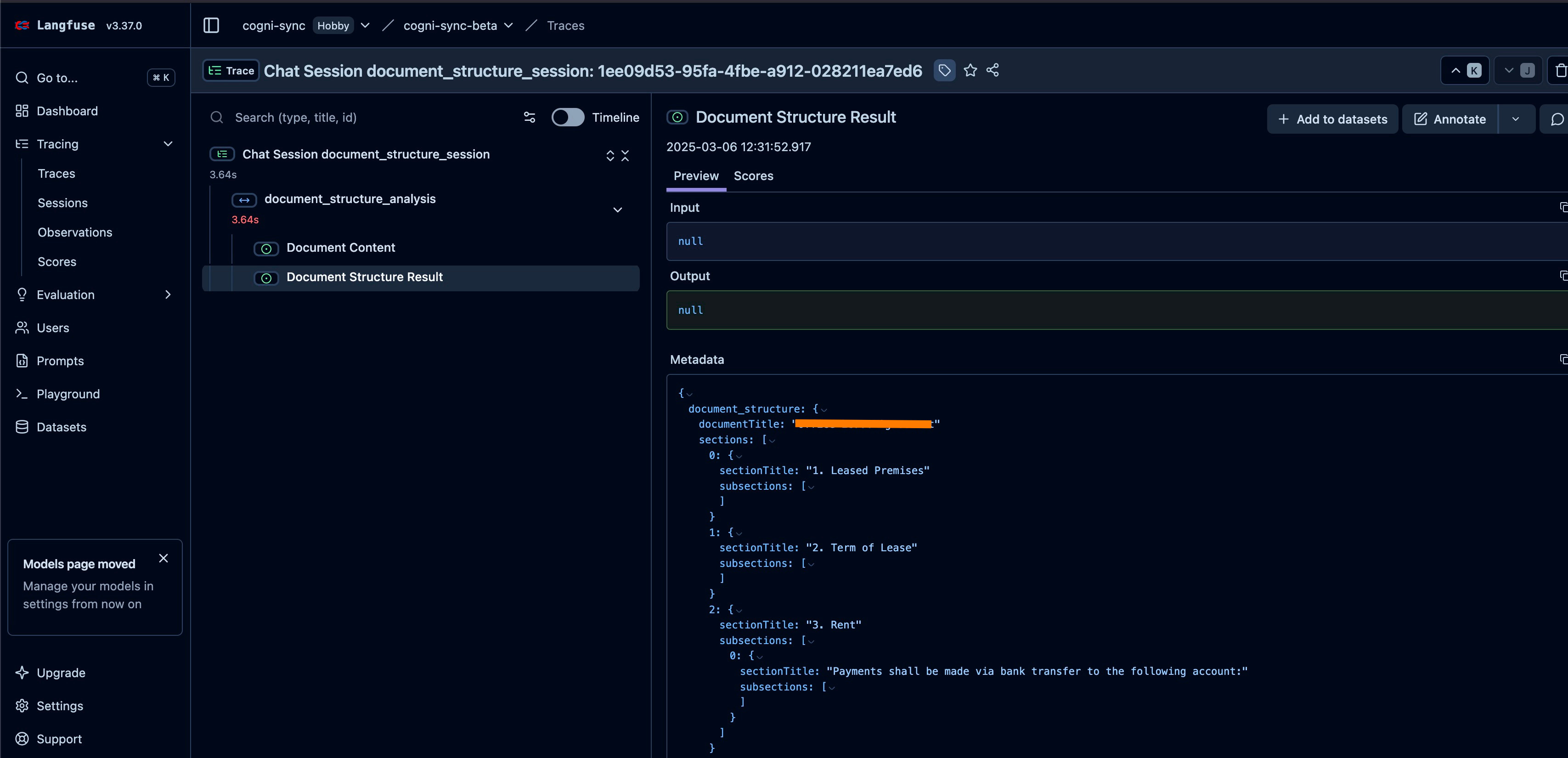
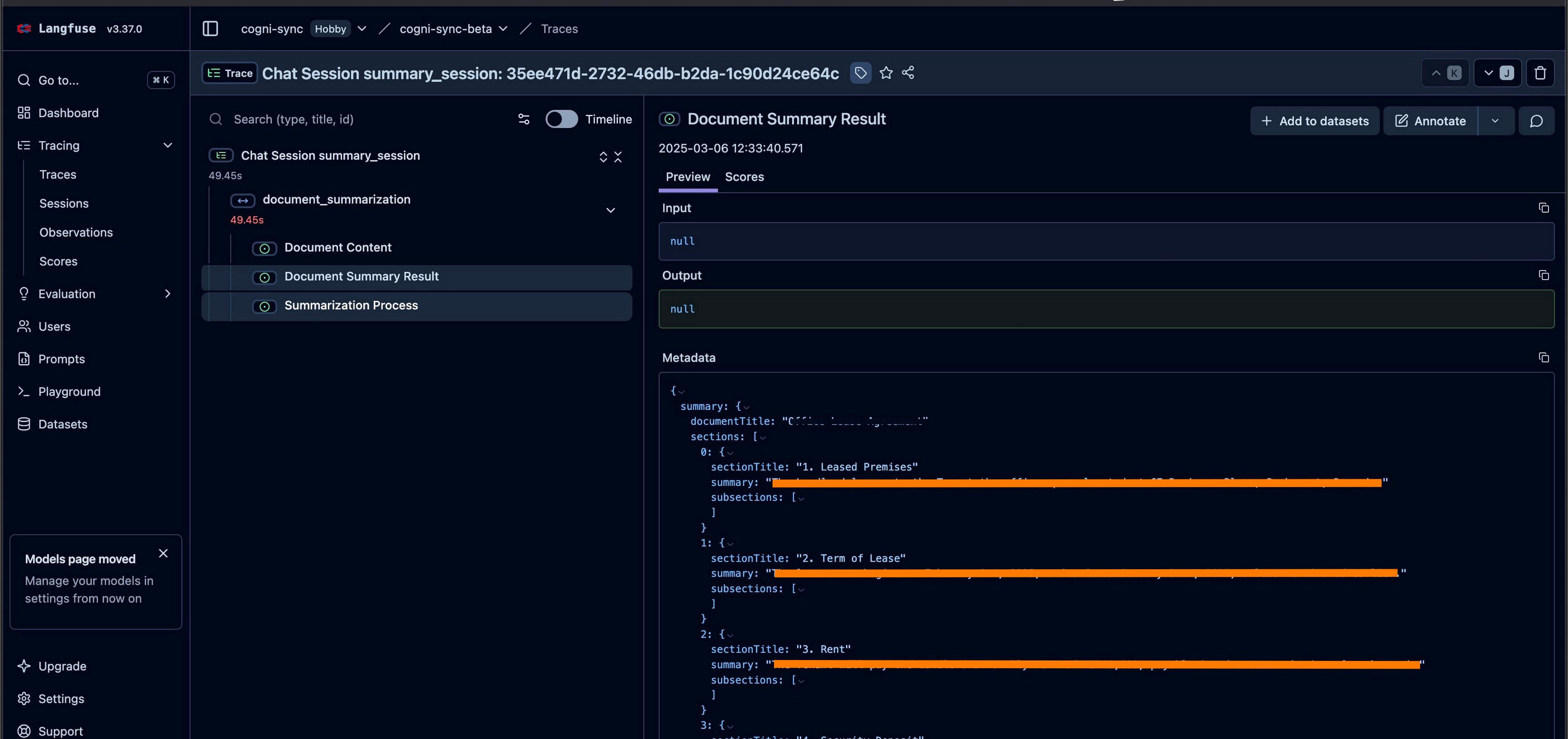
Document structure extraction
Document summary based on document structure
Evaluation of the document summary
Regenerate the summary based on feedback
4 steps must be observed and monitored over time to understand the user behaviour (what type of documents are uploaded) and the system behaviour (how LLM is performing on different types of docs).
In order to do that, I’ve created a Langfuse manager, which register each call to an LLM (trace).

The LangfuseManager is initialized with a public_key, secret_key, and an optional host (defaulting to https://cloud.langfuse.com).
It sets up a connection to the Langfuse API through a Langfuse client instance. The manager also initializes storage for traces (self.traces) and a request counter (self.request_count) to keep track of the number of requests per trace.
When a new LLM call is made, the LangfuseManager first checks if a trace already exists for the given session_id. If not, it creates a new trace with relevant metadata, including tenant_id, session_id, and optional user information (user_id, first_name, last_name). This step ensures that all requests related to a particular session are grouped under a single trace, making it easier to monitor the entire flow of a user session.
The log_chat_request method is responsible for recording the interaction between the user and the LLM:
Metadata Collection: It gathers information from the request and response, such as
session_id,user_id, the query made by the user, and any document-related metadata.Span Creation: A span is created for the process (
process_chat_request), capturing the start and end of the interaction.Document Context Logging: If the request involves a document, the manager logs the document's path, length, and a preview of its content.
User Message Logging: When the user sends a query, it logs the message along with detailed metadata, helping to understand the user's intent.
Model Response Logging: If the response includes a generated answer, the manager logs the model's output, along with the input prompt and model-specific metadata.
Error Handling: Any errors in the response are also logged as events with the "error" level, allowing quick identification of issues.
Request and Response Debugging: The full request and response objects are logged, giving complete visibility into the data flow and helping with debugging.
The log_llm_generation method is specifically designed to log the interaction with the LLM:
Input and Output Tracking: It records the prompt sent to the model and the completion generated, along with the model's name and relevant metadata.
Parent-Child Traceability: The method can link this generation to a parent observation, maintaining a clear hierarchy of operations within a session.
4. Conclusions
Observability is a must in any AI system. Don’t assume your LLM calls are working and the results are promising.
Design an observability model from the beginning, when business logic is designed.
Evaluate and monitor the traces. Understand human behaviour and system behaviour.