
MLOps system design is boring.
The thinking process behind any AI system.

🚨 Alert. This article is dangerously practical—no AI buzzword bingo here. Oh, and did I mention? We have CODE. 🧑💻
Oh, and one more thing… we’re now on 🔗 LinkedIn! Follow for snippets of knowledge.
Key takeaways
MLOps is More Than Just Tools. Focus on reproducibility, scalability, and observability, not just setting up Kubeflow or MLflow.
GenAI Needs MLOps to handle prompt versioning, model drift, and RAG complexities.
Define the problem first before jumping to the latest AI tool. It will save you more time than you think.
AI systems break silently without proper MLOps. Logging, validation, and monitoring are best practices.
Thinking about MLOps principles seems boring or overwhelming, depending on what type of AI engineer you are.
Real MLOps doesn’t happen in 1 day or 1 week. Knowing how to use different tools doesn’t make you an MLOps expert. You must understand the why behind every decision and how your system is impacted if you don’t have different MLOps components. It takes time to understand the whole process, and it takes time to learn how to have arguments to convince the management, the CEO, or other stakeholders.
In the startup era or enterprise field, it is always forgotten that because of time, manpower, or knowledge, but from my point of view, GenAI applications must have the most basic MLOps principles in place. We will discuss these principles later.
So, my objective in these series, which I think will be three articles, is to teach you how to think and build an end-to-end AI system. I want to teach you the why behind each MLOps decision. Don’t get me wrong; so many AI influencers are ‘experts’, but I want to introduce something different and new: the concept of ‘how to think’ a system.
Long story short, in this series, you will learn how to build a real-world AI system and why and when to implement different MLOps principles, using different technologies and frameworks, and most important, yes, CODE.
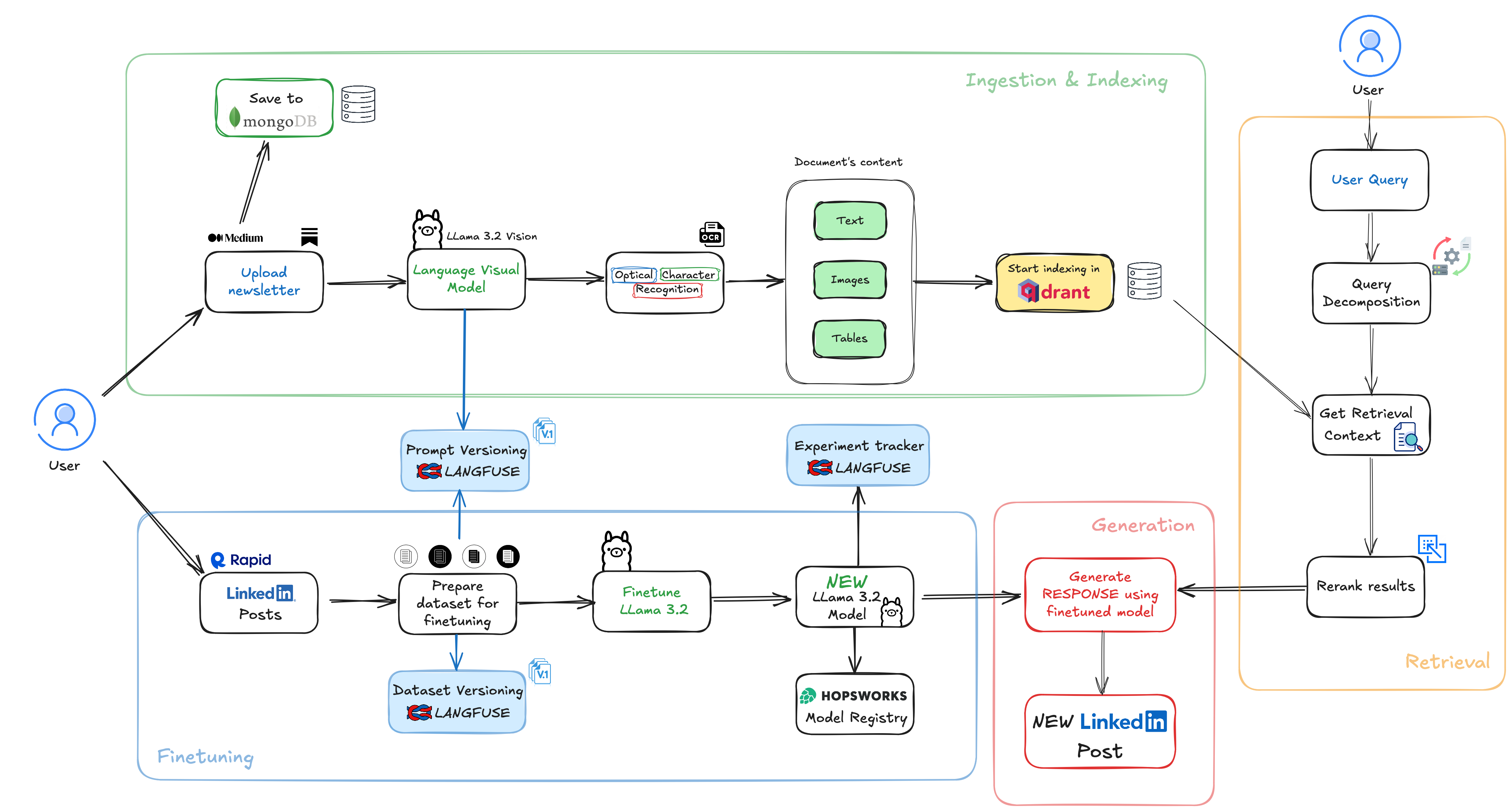
Table of contents
What is MLOps, and what is its comparison with DevOps?
How should I start thinking about an MLOps system?
Understand the lifecycle of an ML system
Why and where should I apply MLOps principles?
Next steps
1. What is MLOps, and what is its comparison with DevOps?
A little bit of history
The origins of MLOps date back to 2015, when a paper entitled “Hidden Technical Debt in Machine Learning Systems " was published. Since then, growth has been particularly strong. The market for MLOps solutions is expected to reach $4 billion by 2025.
MLOps = ML + DEV + OPS
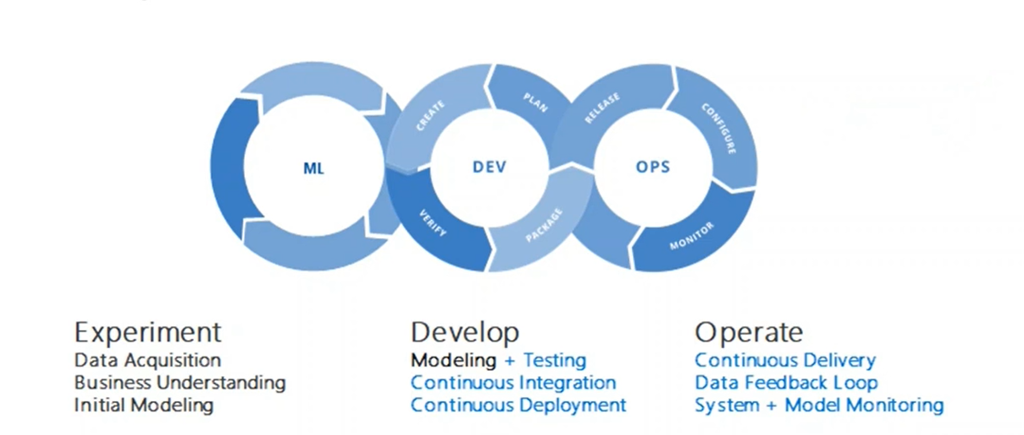
If you’ve worked in software engineering, you probably already know DevOps. The set of practices that automates software development and deployment, ensuring continuous integration, delivery, and monitoring.
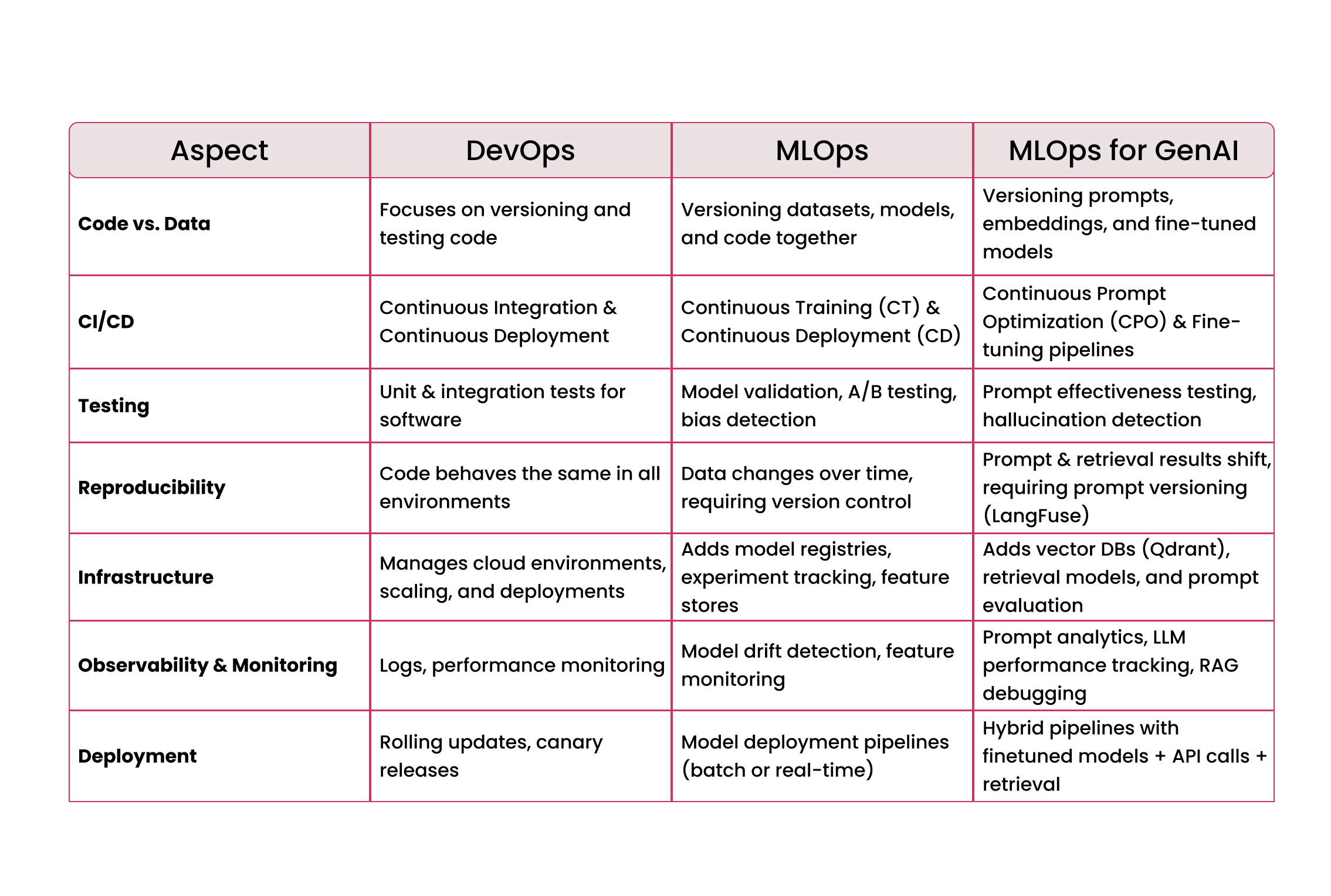
But when it comes to machine learning, things get tricky. MLOps (Machine Learning Operations) is not just DevOps with models. It requires a paradigm shift because models aren't static software artifacts—they evolve based on new data, require retraining, and introduce unique challenges like data drift and model degradation.
Also, GenAI systems have prompts, one of the most important hyperparameters, which must be versioned and monitored. We have hallucinations and many system behaviours that cannot be treated as ‘bugs’.
Why is MLOps essential for GenAI?
For traditional ML models, MLOps is already crucial. But with Generative AI (GenAI), the need for MLOps becomes even more pressing because:
Prompt engineering is experimental – You need prompt versioning (e.g., LangFuse).
Models drift faster – LLMs rely on embeddings that can degrade over time.
Fine-tuning and RAG (Retrieval-Augmented Generation) make AI systems more complex than just API calls to OpenAI.
Production AI isn’t just "call GPT" – It involves ingestion pipelines, retrieval systems, monitoring, and governance.
MLOps is NOT just about tools
Many engineers fall into the "tooling trap"—thinking MLOps is just about setting up Kubeflow, MLflow, or LangFuse. In reality, MLOps is a mindset, ensuring:
Reproducibility – If you retrain your model tomorrow, will you get the same results?
Scalability – Can your AI system handle millions of queries efficiently?
Observability – How do you debug hallucinations or data drift?
2. How should I start thinking about an MLOps system?
Most engineers approach MLOps backwards, they start with tools instead of principles.
They ask, "Should I use Kubeflow or MLflow?" instead of "What problems am I solving?"
Let’s flip the script. Instead of throwing tech at the problem, let’s design the system from first principles.
2.1. Understand the lifecycle of an ML system
Before picking any tools, break down the lifecycle of the system you're building. For example, we have four core phases for the system we’re creating today. Another important aspect of our system is that the main requirement is that everything must be in private mode, on-premise, without cloud components, so NO GPT, Mistral, Claude, or Gemini.
The four components of our system:
Ingestion and indexing → Don’t just choose a tool, understand your data first
The first mistake most engineers make? Selecting a tool before understanding the data.
You might have read about LlamaIndex SimpleDirectoryReader and thought, “Great, it can parse PDFs, HTML, and Word docs, so I’ll use it.”
🚨 Wrong approach. You first need to analyze the structure of your data:
Do you mostly have text-based documents?
Are you dealing with scanned PDFs that require OCR?
Are there tables or images that contain critical information?
🔎 In our case (from the diagram), here’s how I handle it:
Users upload newsletters from Medium, LinkedIn, or other sources.
A multi-modal model (Llama 3.2 Vision) extracts both text and images.
We classify content into text, images, and tables before storing it in MongoDB.
Finally, the structured data gets indexed into Qdrant, making it retrievable for future queries.
Finetuning → as I said earlier, we are talking about on-premises architecture, so we have limited hardware resources. So we need to pay attention at this crucial aspect. Fine-tuning is not always necessary, but it makes sense when:
The base model lacks domain-specific knowledge.
If an LLM isn’t trained on AI newsletters and LinkedIn-style posts, fine-tuning helps it adapt to our content style.
We need a specific response format.
Standard LLMs might not generate posts in an engaging, structured way. Fine-tuning can teach it the right style.
We want to personalize the model’s tone and behavior.
A fine-tuned model can be more consistent than relying on prompt engineering alone.
However, fine-tuning has downsides:
❌ Expensive – Requires training infrastructure and computing resources.
❌ Rigid – Fine-tuned models can't adapt to new data as easily as a RAG system.
❌ Harder to iterate – You need proper dataset versioning to track model improvements.
Retrieval → start simple, then optimize
Do you really need a complicated RAG system? It depends. Before over-engineering retrieval, ask yourself:
Can a naive RAG + fine-tuned model work for my use case?
Is my issue with retrieval or just bad indexing?
What’s the simplest way to test the retrieval first?
Why did I choose to have also a retrieval system in our architecture? For this kind of system, my theory was that I need also external knowledge to augment the fine-tuned model, but you will see in the next lesson that this kind
of system design choices are not always based on something strong, so it’s all about trial and error. It’s important to monitor and observe the system behaviour.
Generation → inference part, where basically everything is aggregated and the final output is ready for the client
3. Why and where should I apply MLOps principles?
Applying different MLOps principles can be complicated, but I will go deeper in the next lessons.
As a rule of thumb, my thinking process when I’m building AI systems is this: 👉 Where in my system can things go wrong and impact the client?
One of the most common problems I see is that engineers overfit their application before deploying it into production. Let’s take the LinkedIn post generator as our practical example.
The classical development approach is to collect some LinkedIn posts, fine-tune the model (it will be overfitted), create the RAG system on a few articles, and make the LinkedIn post. But how do we consider that the users are different? The content is different. Also, we need to know how we analyze the system behaviour, what type of content we use, how many data points we need to optimize our system, and many other variables.
Every AI system has key weak spots where things break silently:
Data Ingestion & Indexing
Problem: Corrupt, outdated, or misclassified data affects retrieval
MLOps solution: Data validation, versioning (LangFuse)
Fine-Tuning
Problem: Model overfits to old trends, making responses outdated
MLOps solution: Experiment tracking, dataset versioning
Retrieval
Problem: Model retrieves irrelevant or incomplete data
MLOps solution: Embedding versioning, metadata filtering
Generation
Problem: Model hallucinates facts or gives inconsistent answers
MLOps solution: Prompt tracking, response validation
MLOps is not just about setting up tools but monitoring what happens after deployment.
✔️ Log everything – Dataset versions, fine-tuned models, prompt changes, response outputs.
✔️ Detect issues early – If fine-tuned models start performing worse, catch it before clients notice.
✔️ Make iteration easy – You should be able to rollback a model, prompt, or retrieval strategy in minutes.
4. Next steps
Now that we’ve established the core principles behind designing an AI system with MLOps in mind, it’s time to move from theory to practice.
In the next lessons, we will go step by step through the development of our LinkedIn post generator, focusing on the three key stages of the system:
Ingestion + Indexing + Retrieval
How do we efficiently process and store newsletters?
How should we index data to ensure fast and relevant retrieval?
What retrieval strategies should we use before introducing complexity?
Fine-Tuning
When does fine-tuning actually help, and when does it just add unnecessary cost?
How do we track fine-tuning experiments and prevent overfitting?
What role does retrieval play in reducing the need for fine-tuning?
Generation: producing the final linkedIn post
How do we structure the output to ensure high-quality content?
How do we validate responses and monitor system performance?
What MLOps principles apply to tracking prompts and evaluating outputs?
Each lesson will go deep into implementation details with real code, showing not only how to build each component but also why MLOps principles are essential at every step.
Next article is published?
Excellent article, Alexandru!