
Data preparation for function tooling is boring
Lesson 2: The most boring part that you fail without

🚨 Alert. This article is dangerously practical; no AI buzzword bingo here. Oh, and did I mention? We have CODE. 🧑💻
Oh, and one more thing… we’re now on 🔗 LinkedIn! Follow for snippets of knowledge.

This is going to sound boring... and it is.
Everyone's building AI agents that call functions.
Everyone's excited about the latest open-source "function calling" capabilities.
Every GitHub repo promises "Claude-level function calling with just 3 lines of code!"
But nobody, and I mean nobody (except my friends Miguel Otero Pedrido and Alex Razvant ) – is talking about the unsexy backbone that makes it all work: the data preparation.
Because let's face it: Your agent is only as good as the data you used to train it.
Here's something the "prompt engineering is all you need" crowd doesn't want to admit: there's a limit to what small language models can do without fine-tuning, especially on the edge.
Let's look at the data: 72% of enterprises are now fine-tuning models rather than just using RAG (22%) or building custom models from scratch (6%). This isn't a trend, it's because fine-tuning works when other approaches fail.
The decision to fine-tune isn't arbitrary. As Maxime Labonne’s research shows, you need fundamentally different volumes of data depending on your goal:
Task-specific fine-tuning (like function calling): 10k-100k examples
Domain-specific adaptation: 100k-1M examples
General-purpose training: >1M examples
Function calling sits firmly in that task-specific category, but here's the trick: those 10- 100k examples need to be high quality and properly structured.
When do we decide to fine-tune?
From my personal experience, the decision to fine-tune is always difficult. It depends on many variables, including time, costs, experience, the project's complexity, and the device on which the system is run.
I recommend spending some time defining the domain expertise of your AI system, which has an SLM component.
What problem are you trying to solve with your system?
Is it a RAG enough?
That’s the question I always ask before touching a fine-tuning pipeline.
Because yes, RAG is the easiest first step.
You build a smart retrieval layer, point it to your documentation or tool list, and use a base model to generate answers in context.
It’s fast.
It’s flexible.
It doesn’t need a custom model.
And it works… until it doesn’t.
But here’s the catch: function calling is not a context-retrieval task.
It’s a reasoning + structure generation problem.
In my experiments, even with RAG pipelines that retrieved perfect tool specs (with examples!), the model still:
hallucinated JSON keys
failed to match function names to the user intent
or returned the right answer… in English.
Why? Because knowing is not the same as doing.
Function calling is not trivia. It’s behavior.
So if you're building:
A customer support bot answering dynamic FAQs → use RAG.
A financial advisor who reads live market trends → uses RAG.
An on-device agent that mutes your mic or opens your calendar?
→ You'd better fine-tune.
We will go deeper with RAG vs Fine-tuning in our 3rd lesson.
This is a 4-part course.
If you’ve missed it, here’s Lesson 1 of this course:

Check out the full course here:



Table of contents
Dataset preparation architecture
How do we really prepare our dataset? Entire pipeline generation
MLOps principles for dataset preparation
1. Dataset preparation architecture
Fine-tuning doesn’t start with code. It starts with intent and the definition of what problem the AI system solves.
If your dataset doesn’t reflect what your assistant is supposed to do, with what tone, with what tools, and under what ambiguity, then you’re not fine-tuning an agent. You’re fine-tuning a guessing machine.
The architecture of building a custom dataset for function calling for SLM can look pretty complex, but in practice, yes, you can’t skip steps.
I will explain step by step the whole architecture:
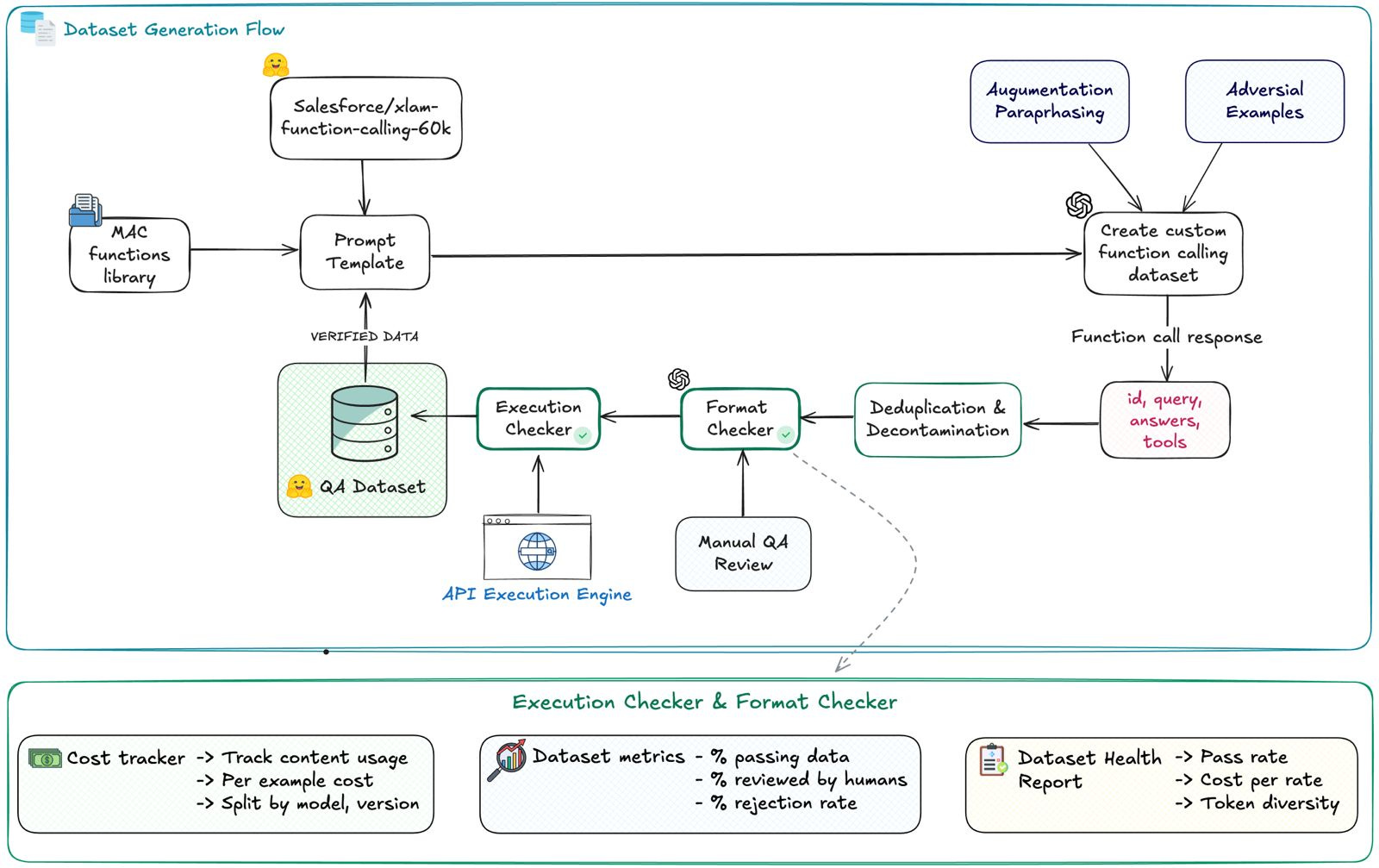
But first, let’s start with the “WHY.”
Why do we really need such an architecture for dataset generation?
Why not just grab an already-cleaned Alpaca dataset from HuggingFace?
Because pre-existing datasets aren’t tailored to the specific function-calling tasks we need. They might contain general instruction-following data, but not the kind of structured, fine-grained mapping from natural language to your laptop or phone’s API functions—like muting audio, setting an alarm, or opening a specific file.
That’s the difference between AI engineering and AI vibing. Do you feel the struggle? (I’m kidding... but also not.)
Always start with WHY and WHAT.
So what are we building in this course?
A custom Siri-style AI system. One where a small fine-tuned model understands natural instructions and can accurately map them to real, executable functions. You can’t expect a raw Gemma 1B, LLaMA 3.1, or Mistral model to magically know how to turn "mute my mic" into mute_microphone().
TOOLS = {
"lock_screen": {
"description": "Locks the laptop screen.",
"parameters": {},
"args": {},
"templates": [
"Lock the screen",
"Please lock my laptop",
"Activate screen lock",
],
},
"get_battery_status": {
"description": "Returns battery level and charging status.",
"parameters": {},
"args": {},
"templates": ["What's my battery status?", "Is my laptop charging?"],
},
"search_google": {
"description": "Searches Google for a query.",
"parameters": {"query": {"description": "Search query", "type": "str"}},
"args": {"query": ["how to bake bread", "latest AI news", "best python tips"]},
"templates": ["Search Google for '{query}'", "Can you search: {query}?"],
},
"set_volume": {
"description": "Sets system volume (0–100).",
"parameters": {"level": {"description": "Volume level", "type": "int"}},
"args": {"level": [10, 30, 50, 70, 90]},
"templates": ["Set volume to {level}", "Adjust sound to {level} percent"],
},
"create_note": {
"description": "Creates a note using the Notes app.",
"parameters": {
"title": {"description": "Title of the note", "type": "str"},
"content": {"description": "Content of the note", "type": "str"},
},
"args": {
"title": ["Groceries", "Project Ideas"],
"content": ["Buy milk and eggs", "Build an AI assistant"],
},
"templates": [
"Create note '{title}' with content '{content}'",
"Make a new note: {title} - {content}",
],
},
}2. How do we really prepare our dataset?
There’s a reason this section comes after the “why.” You don’t start with code. You start with intent.
Function-calling isn’t about creating clever prompts.
It’s about creating behaviour. And behaviour, like any system, are learned through examples.
Not just any examples, but semantically correct, structurally sound, diverse, and executable examples.
Before diving into code, it's crucial to understand the importance of studying existing datasets in the domain you're working on.
Salesforce's xlam-function-calling-60k dataset is a valuable resource for function-calling applications.
This dataset, generated by the APIGen pipeline, comprises 60,000 high-quality examples designed to train AI models to execute function calls based on natural language instructions.
The dataset's structure includes:
Query: A natural language instruction.
Tools: A list of available functions with their descriptions and parameters.
Answers: The specific function calls with arguments that fulfill the query.
Each data point undergoes a rigorous three-stage verification process: format checking, actual function execution, and semantic verification, ensuring over 95% correctness.
By analyzing this dataset, you can gain insights into crafting semantically correct, structurally sound, diverse, and executable examples for your own function-calling models.
Also, this dataset will be used as a few-shot prompting in our dataset generation pipeline.
You can check more here → https//huggingface.co/datasets/Salesforce/xlam-function-calling-60k
2.1. Define the function library
The dataset preparation pipeline starts with a domain-specific function library. This is not just a JSON spec of what your tool can do, but a living API of what the assistant should be able to execute.
For our project, a custom Siri-like agent that runs on-device, we define functions like:
def lock_screen() -> str:
try:
subprocess.run(["pmset", "displaysleepnow"])
return "Screen locked"
except Exception as e:
return f"Failed to lock screen: {e}"
def get_battery_status() -> dict:
try:
battery = psutil.sensors_battery()
return {"percent": battery.percent, "charging": battery.power_plugged}
except Exception as e:
return {"error": str(e)}
This structure is essential. These functions act as the ground truth. If your training data doesn't faithfully represent this library's capabilities and limitations, no fine-tuning will magically make your model behave.
2.2. Define the interface between natural language and executable code.
Before you can generate any data, run any prompts, or fine-tune any models, you need to teach your system what it’s actually capable of doing.
In a function-calling agent, every tool your agent uses corresponds directly to a Python function. These functions must be clearly described, not just for the model’s benefit, but for your own sanity as an engineer.
This step is deceptively simple, yet fundamental. It’s not just about writing code that works. It’s about giving each function:
a clear name
a description in natural language
a list of parameters, with types
example values for those parameters
and critically a set of natural language templates that describe how a human might request this function
Here's a snapshot of what this might look like:

These definitions do several things at once:
They help generate synthetic training data via templates.
They serve as in-context examples for LLM prompting.
They guide users and developers when expanding or maintaining the function library.
And most importantly, they anchor the model’s understanding of what each function does.
Notice how these definitions balance structure (parameters, args) with semantics (description, templates).
You want your LLM to learn that “Mute the sound” and “Set volume to 0” are semantically equivalent, but only one of those maps cleanly to a function call.
Your templates are the scaffolding that helps the model bridge that gap.
2.3. Generate the dataset
Once you’ve defined what your tools are and what they’re supposed to do, the next phase is about generating high-quality, varied examples of how those tools should be used, and how they shouldn’t.
This is the heart of your dataset, the part that bridges your function library to the real-world instructions your model will have to handle. It’s not just about quantity. It’s about coverage: edge cases, natural variation, adversarial phrasing, and meaningful failure.
Our generation strategy consists of four stages:
2.3.1. Single-tool examples: the core behaviour
We begin by generating canonical examples using one tool per prompt. These examples define the atomic behaviour your assistant should be able to execute.
Each tool in the library comes with a list of templates. These templates are short, human-like commands with variable slots filled in using example arguments.

This process is repeated for each tool, generating a balanced baseline across the assistant's entire action space.
Why this matters: Single-tool examples provide clarity, reduce ambiguity, and teach the model what success looks like when the task is simple and direct.
2.3.2. Multi-Tool Examples: expanding behaviour through composition and few-shot prompting
Once we’ve covered the basics, single-tool tasks, atomic behaviour, we begin to scale complexity by asking the model to handle instructions that require multiple tool invocations.
This step pushes the assistant beyond recognition and into reasoning. Multi-tool prompts test whether the model can:
Understand compound tasks
Identify which parts of the instruction map to which tools
Maintain correct argument formatting for each function
But generating these instructions isn't trivial. Unlike single-tool prompts, which can be composed deterministically, multi-tool prompts need to feel realistic, coherent, and naturally integrative. That’s where the LLM comes in.
Prompting the model to generate multi-tool instructions
We built a synthetic data generation loop that:
Randomly selects two tools from the available set.
Samples plausible argument values for each tool.
Constructs a tool summary payload , readable descriptions for each function and its arguments.
This payload is passed into a prompt template, instructing the LLM to write a natural, specific instruction that requires both tools.
Here’s a snippet from the prompt:
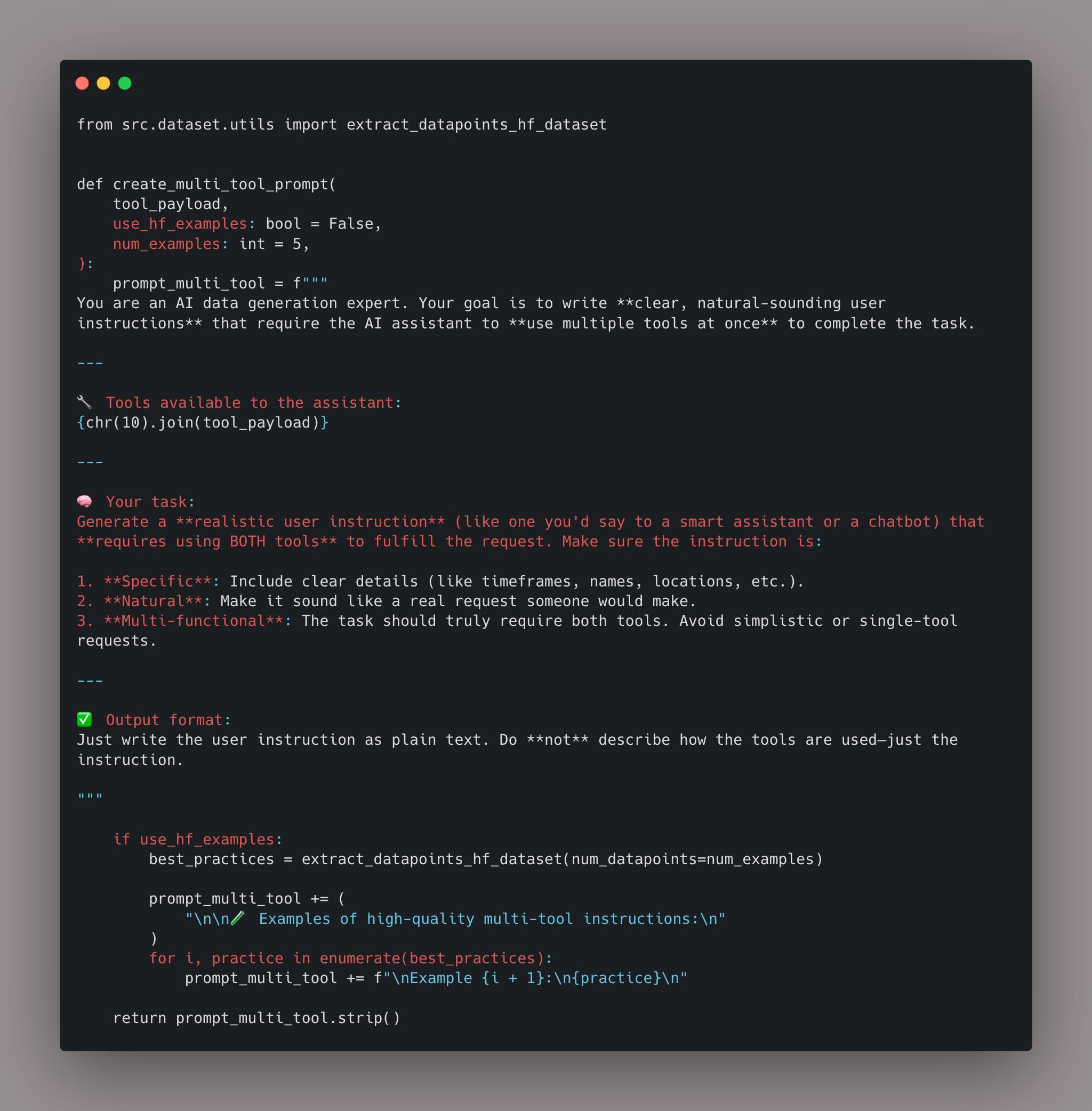
What’s important here is not just the structure but also the guidance. We explicitly prompt the model to avoid simplistic phrasing, aim for specificity, and craft integrated behavior.
Injecting human-like grounding: examples from real datasets
To make this even more effective, we provide a few-shot examples drawn from the Salesforce xlam-function-calling-60k dataset.
Using the extract_datapoints_hf_dataset() utility, we pull high-quality entries directly from this dataset, format them, and embed them as few-shot examples into the LLM prompt:

This technique gives the model a concrete reference, patterns of good behavior, before it generates its example.
Why this matters: Grounding LLM prompts with real examples acts as a form of semantic alignment. You’re not just telling the model what “good” looks like you’re showing it. And that makes a measurable difference in quality, fluency, and diversity.
Example output
Here’s what a generated entry might look like:

Notice how:
The instruction is natural and plausible.
It reflects a real-world use case (leaving the house, prepping a reminder, muting sound).
It maps cleanly to two distinct, well-structured function calls.
Multi-tool generation is when you start to simulate real behavior in real environments. It’s when a dataset becomes more than a training artifact, it becomes a representation of what your assistant is supposed to do.
But it’s only meaningful if we can verify that these examples work and that’s where we go next.
2.3.3. Unknown Intents: teaching the model to not act
Most people focus on teaching language models what to do.
However, one of the most important lessons in production systems is what not to do.
This is especially true in function-calling setups.
You don’t want your assistant guessing what to execute. The model should not hallucinate a function call if a user asks for something unsupported, such as sending an email, booking a flight, or checking the weather. It should respond with nothing.
That behaviour needs to be taught.
We do this by injecting negative examples — natural user instructions that don’t map to any known tool:

The dataset entries for these look like this:
{
"id": 412,
"query": "Can you book me a ticket to Barcelona?",
"answers": [],
"tools": []
}
No answers, no tools, just a clear signal to the model: this is out of scope.
Why this matters
By default, LLMs are trained to help you. They don’t know how to listen. They know that they have to answer your query.
If you don’t include these negative points, your model will try to be “helpful” in all the wrong ways. It may start making up tools, arguments, or partial outputs, which quickly becomes dangerous in a live system.
Rejection handling is part of reliable behavior.
2.3.4. Paraphrasing: variety without breaking structure
We paraphrase once we’ve generated a base dataset, including single-tool, multi-tool, and negative examples.
The goal is simple: we want linguistic diversity without changing the underlying meaning or structure of the example.
Using an LLM, we pass each query through a prompt like:
Paraphrase the following instruction while preserving its meaning. Keep it short, clear, and realistic.
We then regenerate the prompt in a new form, same behavior, new phrasing.
For example:
Original:
"Create a note called 'Groceries' that says 'Buy milk and eggs'"Paraphrased:
"Can you write a grocery note with the items milk and eggs?"
We maintain:
The intent
The tool to be called
The parameters
The overall structure
Only the surface form changes.
Each paraphrased sample is stored with a new ID and linked back to the original structure:
{
"id": 1041,
"query": "Mute my mic and jot down a note titled 'Daily Tasks'",
"answers": [...],
"tools": [...]
}
Real users don’t speak in templates. They rephrase, improvise, and talk casually. Paraphrasing helps expose the model to the latent space of meaning, not just rigid patterns.
And unlike most data augmentation strategies, this one is semantically aware. We're using language to teach language, which is the entire point of LLMs.
By the end of Step 3, we’ve built a dataset that reflects:
Core behaviors
Composite tasks
Out-of-scope rejections
Linguistic variation
We now have a complete instruction-function map, ready for validation and fine-tuning.
But just because the data looks clean doesn’t mean it is.
In the next section, we shift gears and enter the quality control phase, including deduplication, format validation, and execution tests, which are essential for turning synthetic data into reliable supervision.
2.4. Validating and verifying your generated dataset
So you’ve generated hundreds, maybe thousands, of synthetic examples. It looks like a dataset. The JSON is pretty. The queries are diverse. The function calls seem right.
But let me ask you something:
Have you run them?
Have you tested what happens when the model says:
"Mute the microphone and open my calendar to today."
And then… you actually try to execute that?
That’s where most datasets fall apart.
It’s not enough for examples to look correct.
In a production-grade function-calling system, correctness means structure, semantics, and execution all align.
This section is about using your synthetic examples to provide reliable supervision, which requires real quality control.
Let’s break it down.
2.4.1. Deduplication, reducing noise
We used an LLM to generate our dataset. As you know, LLMs are remarkably good at repeating themselves in slightly different ways. This means that even with structured generation, you’ll end up with examples that are semantically (and sometimes literally) duplicates.
We use semantic deduplication via Sentence Transformers:
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("all-MiniLM-L6-v2")
similarities = util.pytorch_cos_sim(query_embedding, existing_embeddings)
This lets us detect duplicate meaning, not just duplicate phrasing. If an example is too close to one we've already accepted, we drop it.
Overfitting doesn’t just happen when your model sees the exact string. It occurs when it memorizes ideas without seeing enough variation. Deduplication helps prevent that.
2.4.2. Format validation, enforcing structure
Every example in your dataset must follow a consistent schema. But structure isn’t always enforced at generation time, especially when you’re prompting an LLM to produce text.
We run every data point through a format checker that verifies:
Presence of required keys (
query,answers,tools)Those arguments match the function spe.c
That empty answers exist only for unknown intents
2.4.3. Execution testing , from text to action
It’s easy to write a function call like:
{
"name": "set_volume",
"arguments": {
"level": "high"
}
}But what happens when set_volume function expects an integer between 0 and 100? “high” isn’t just wrong, it’s dangerous. If you fine-tune your model on it, you inject bugs directly into your assistant's brain.
So we actually run the calls.
We load up our function registry and attempt to execute each function call in the dataset in a sandboxed environment:
report = run_execution_checker_parallel(dataset, available_function_calls)We record:
Total calls made
How many succeeded
How many failed
What the traceback was on failure
Each function is tested independently, and we generate a report like:
[✓] Execution report saved to execution_report.json
✅ Executed 10 calls
✔️ Passed: 10
❌ Failed: 0
📊 Success Rate: 100.0%Nothing in the LLM world enforces reality like code execution. It’s the hard edge between language and logic. Execution tests are where you catch bad templates, mismatched arguments, outdated tool specs, or plain errors.
3. MLOps principles for dataset preparation
Once your dataset is generated and validated, you face a new problem: how to manage it over time.
Because your data isn’t static.
3.1. Dataset versioning
You’ll quickly learn that "the dataset" isn’t one thing. It’s a living, growing artifact. You may start with v0.1 — 500 examples generated with GPT-4.
Then you fine-tune on v0.2 using a new paraphrasing strategy. Then you add new tools and regenerate everything in v0.3.
If you’re not versioning, you’re flying blind.
A simple strategy here:
Save every generated dataset as a JSON file (
dataset-v0.2.json)Log metadata: model used, date, function schema hash
Upload to Hugging Face for transparency, reproducibility, and collaboration
You can push versions using the datasets library:
from datasets import Dataset, DatasetDict
dataset = Dataset.from_list(your_examples)
dataset.push_to_hub("your-org/function-calling-dataset", config_name="v0.3")
Now you have:
A versioned dataset registry
Public or private access
Diffs across time
Provenance for every fine-tuning run
If model regresses, you must know which data caused it.
Versioning gives you blame, rollback, and reproducibility.
3.2. Cost tracking: LLMs are not free, and you should know where the tokens go
Cost becomes a real constraint when you’re generating synthetic examples using commercial LLMs.
That’s why we log:
Token usage per prompt and response
Cost per example (based on current API pricing)
Aggregate dataset cost
Cost breakdowns by model version
Each example is annotated like this:
"usage": {
"prompt_tokens": 61,
"completion_tokens": 138
},
"cost": 0.00274
This is where tools like Langfuse come in.
Langfuse acts as an observability and logging layer for LLM-generated content. You can:
Track how much each example costs
Tag examples by tool coverage or scenario
Monitor cost spikes in multi-tool generation
View token distribution per dataset version
Fine-tuning costs are predictable. Prompt generation is not. If you're not tracking this now, you will regret it when your LLM bill hits $1,400 for a “quick experiment.”
3.3. Dataset health report: metrics for maintainability
You wouldn’t deploy a model without monitoring its accuracy. Why deploy a dataset without monitoring its quality?
Our pipeline outputs a dataset health report that tracks:
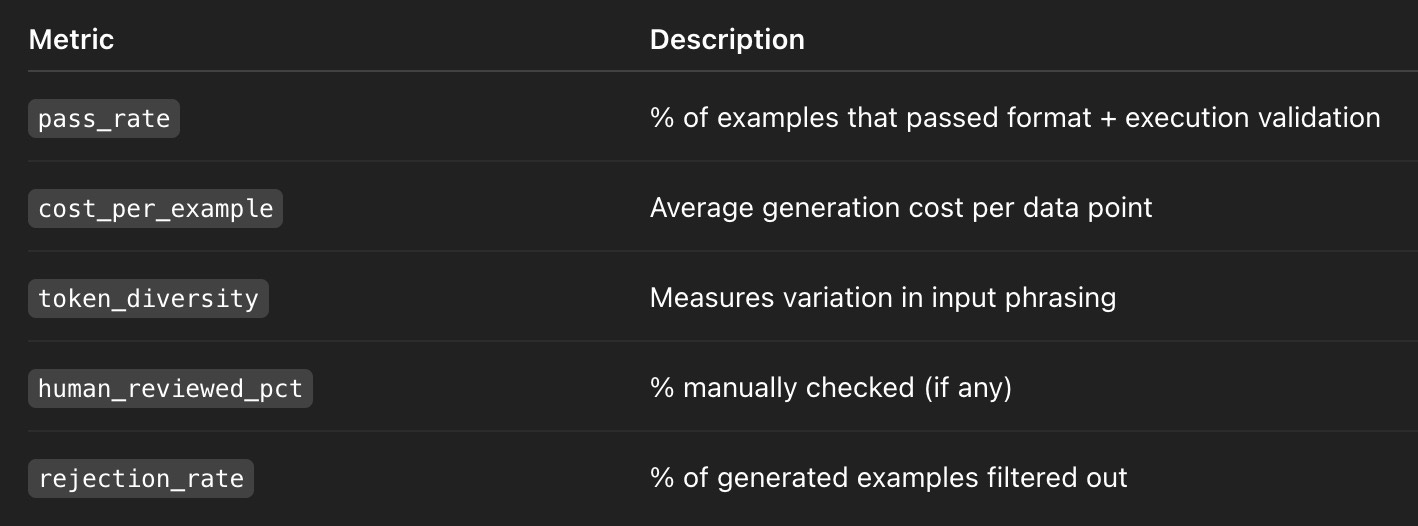
They’re the difference between “synthetic” and “reliable”, between something that looks good on paper and survives in production.
You should automate this. If you can’t answer “How healthy is this dataset?”, then you’re just assuming.
Wrapping Up
If you’ve followed this far (drop a 🔥 in the comments, it’s been a journey), you should now have:
A modular system for generating high-quality examples
A clear process for paraphrasing, rejecting, and validating them
Infrastructure to track versioning, cost, and quality over time
Coming Up Next: Fine-Tuning Your Function-Calling Model
In the following article, we’ll discuss about fine-tuning phase.
We’ll show you how to:
Train a small model (like LLaMA 3.1B or Gemma 2B) on your dataset
Use LoRA adapters for fast, cheap iteration
Evaluate model output with real function-call tasks
Benchmark accuracy, structure, and execution
Decide when your model is "good enough" to go on-device
It’ll be hands-on.
It’ll include real code, real configs, and real gotchas.
And it’ll be the moment you finally see your assistant do what it was designed to do.
🔗 Check out the code on GitHub and support us with a ⭐️
🔥🔥🔥🔥