
Building the Agentic GraphRAG System—Data Pipeline, Monitoring, and Orchestration
Part 3/4 of Uplifted RAG systems


Introduction
In today’s fast-moving world of research, having a system that’s smart, scalable, and reliable for analyzing academic literature is more important than ever. This document walks you through a solution that brings together data pipelines, graph databases, vector embeddings, and real-time experiment tracking. We’ll show you how raw data turns into a knowledge graph, how tools like CometML Opik help track and monitor metrics, and how autonomous agents make the most of it all with a well-designed setup. By combining retrieval and generation into one seamless pipeline, we not only hit high accuracy but also get clear insights into how the system performs at every step.
🔗 This is a 4-part series. The content is split as such:
Part 1: The RAG Challenge: Exposing the Gaps in Modern Retrieval-Augmented Generation
Part 3: Building the Agentic GraphRAG System—Data Pipeline, Monitoring, and Orchestration
Table of contents:
Data Pipeline
1.1 From Raw Data to Structured Knowledge
1.2 Neo4j: Building the Knowledge Graph
1.3 Scaling Data Ingestion
1.4 Bridging Graphs and VectorsCometML Opik Integration
2.1 Metrics Collection
2.2 Experiment Tracking
2.3 The Power of Real-Time InsightsAgent Architecture
3.1 The Core RAG Architecture
3.2 Paper Lookup Tool
3.3 Data Models and StructureAgent Integration Through Tools and CometML Opik
Intelligent Tool Orchestra
System Orchestration: The Coordinator Pattern
6.1 Orchestrated Initialization
6.2 Service Layer Integration
6.3 Intelligent Message Processing
6.4 Resource Lifecycle Management
6.5 Production Benefits of Coordinated ArchitectureConclusions
1. Data Pipeline
The foundation of our Agentic GraphRAG system lies in the data pipeline. For this project we chose arXiv Dataset from Kaggle. Working with this dataset presented unique challenges, particularly in handling the massive scale of academic papers and their intricate relationships. We developed a multi-stage pipeline that transforms raw academic data into a rich, queryable knowledge graph.
1.1 From Raw Data to Structured Knowledge
We built a streamlined preprocessing pipeline that transforms raw paper metadata into a structured format
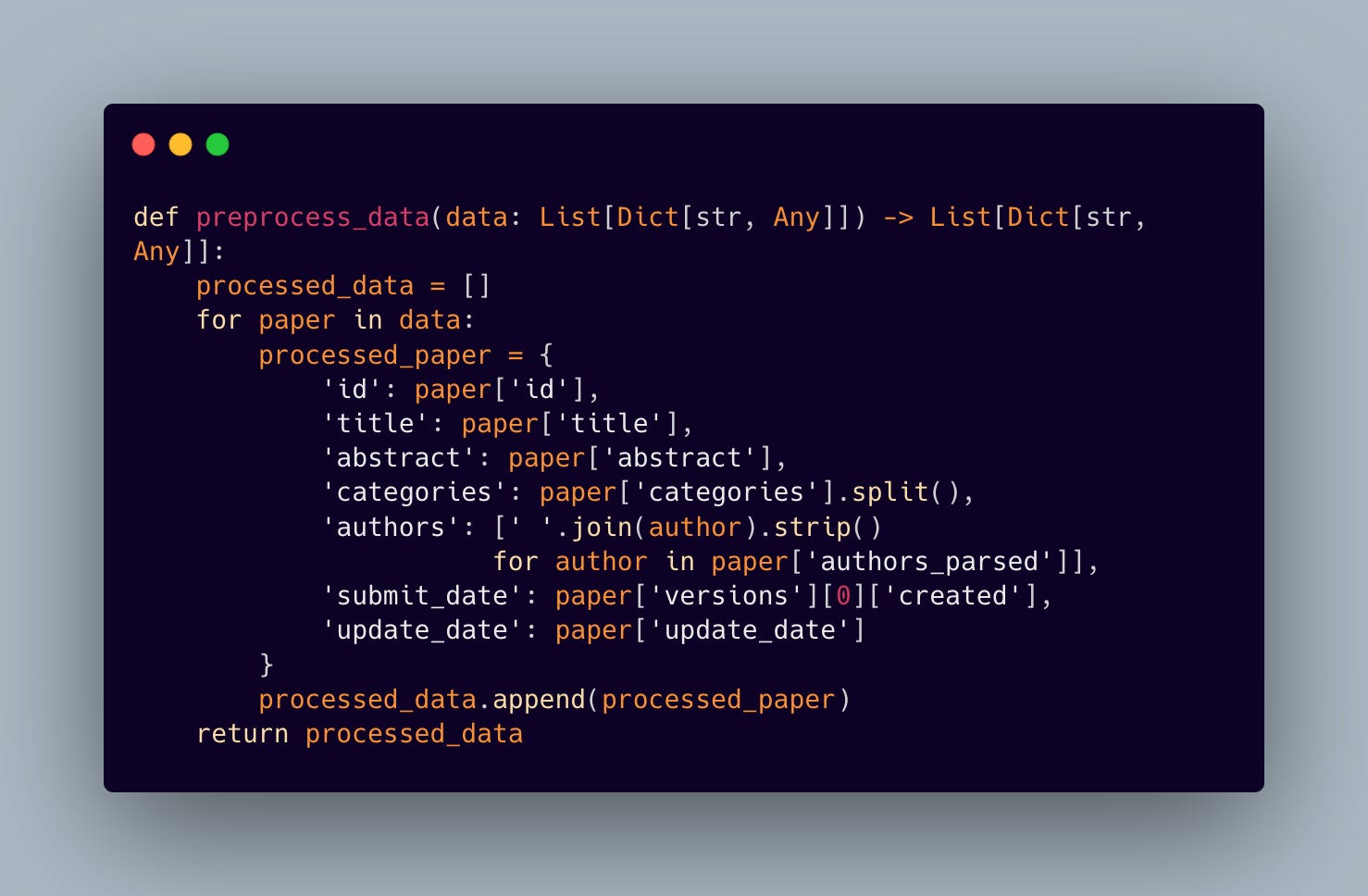
This step is crucial because we need a properly structured and clean data for our graph database ingestion
1.2 Neo4j: Building the Knowledge Graph
We chose Neo4j as our graph database for its robust support of complex academic relationships. The schema design reflects the natural structure of academic literature, where papers connect to authors and categories in a many-to-many relationship. To maintain data integrity, we enforce constraints across our node types:
The schema is being enforced through constraints:
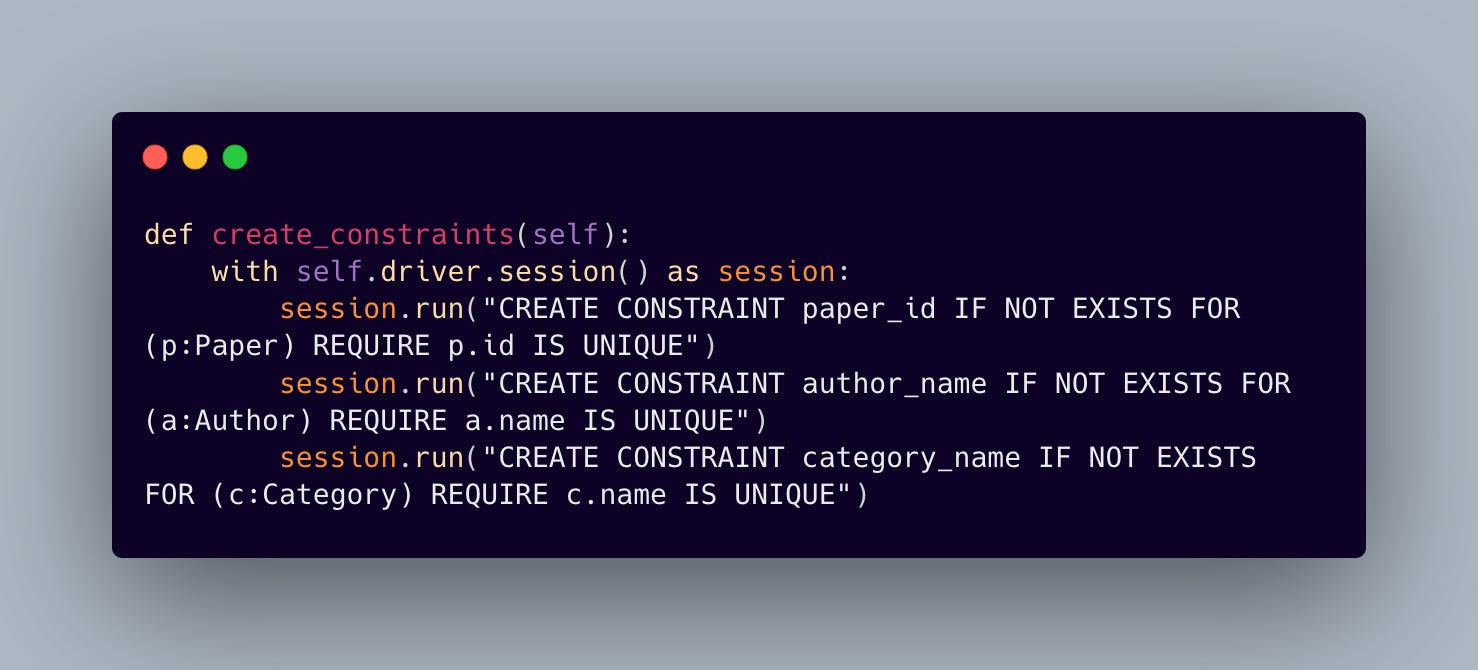

1.3 Scaling Data Ingestion
Processing academic papers at scale can get tricky due to the size of the dataset. Our parallel ingestion system leverages multiprocessing to efficiently handle large datasets:

This approach significantly reduces ingestion time while maintaining data consistency through careful batch processing and optimized Neo4j MERGE operations.
1.4 Bridging Graphs and Vectors
The final piece of our data infrastructure integrates Langchain’s Neo4jVector store, enabling semantic search capabilities alongside graph operations:
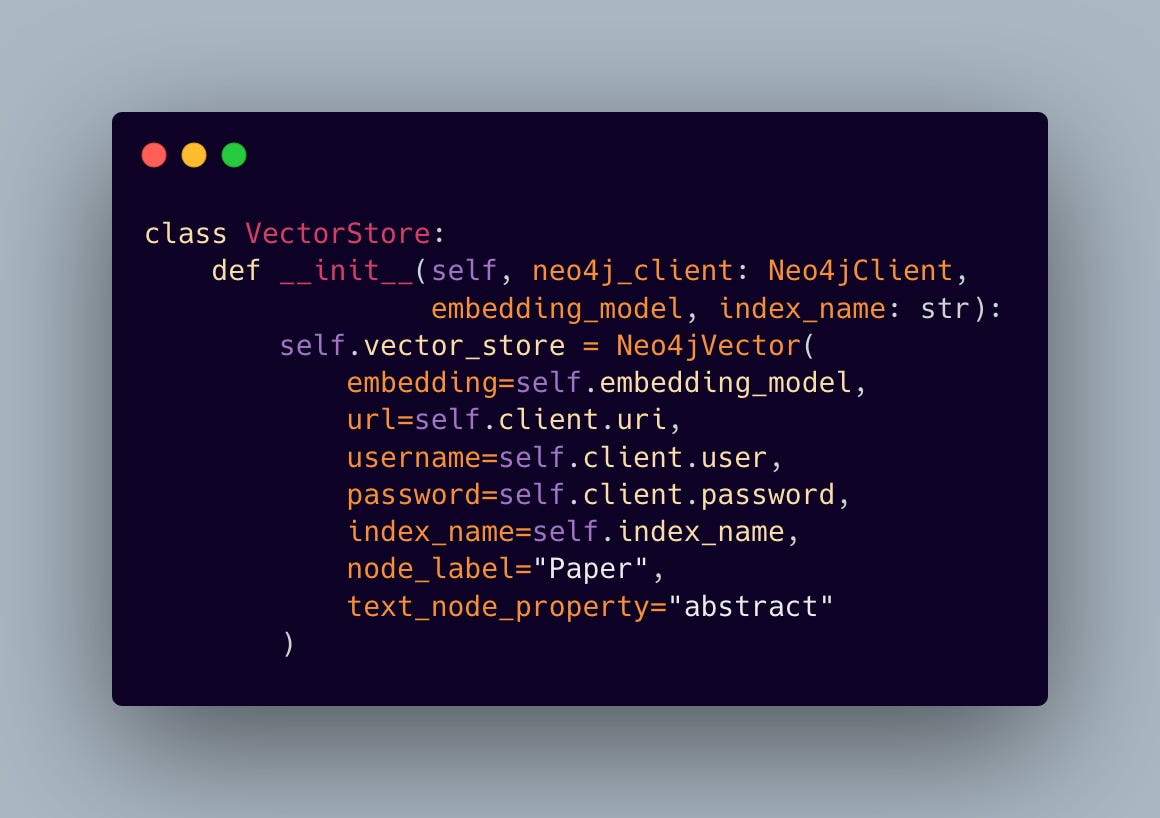
This hybrid approach combines the best of both worlds: the relationship-aware querying of graph databases and the semantic understanding of vector embeddings. The result is a system that can both navigate the explicit connections between papers and understand their semantic similarities.
Through this carefully architected pipeline, we’ve created a data foundation that doesn’t just store academic papers — it understands their relationships, enables semantic search, and scales efficiently with growing datasets. This rich data infrastructure forms the backbone of our agentic RAG system’s ability to provide intelligent, context-aware responses.
2. CometML Opik Integration
At the heart of our implementation lies a carefully crafted metrics collection system. Rather than simply throwing numbers into the void, we’ve designed a structured approach that captures the pulse of our RAG system:
2.1 Metrics Collection
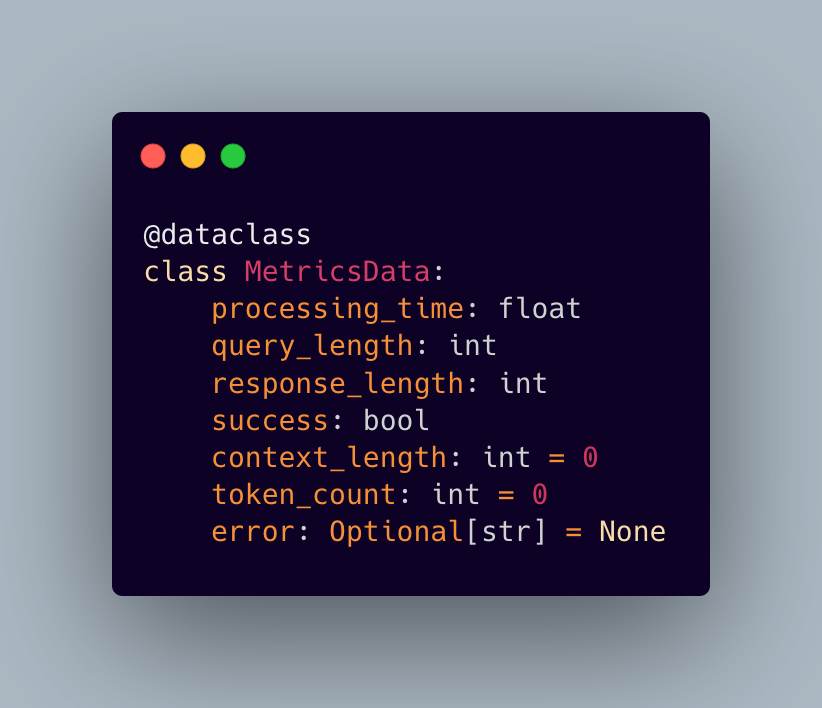
This class allows us to track:
Processing times and latencies
Input/output sizes
Success rates
Error patterns
Token usage
2.2 Experiment Tracking
Our implementation truly shines is in how we leverage CometML Opik’s experiment tracking capabilities. We’ve built an ExperimentTracker that doesn’t just collect data — it weaves a narrative about our system’s performance:
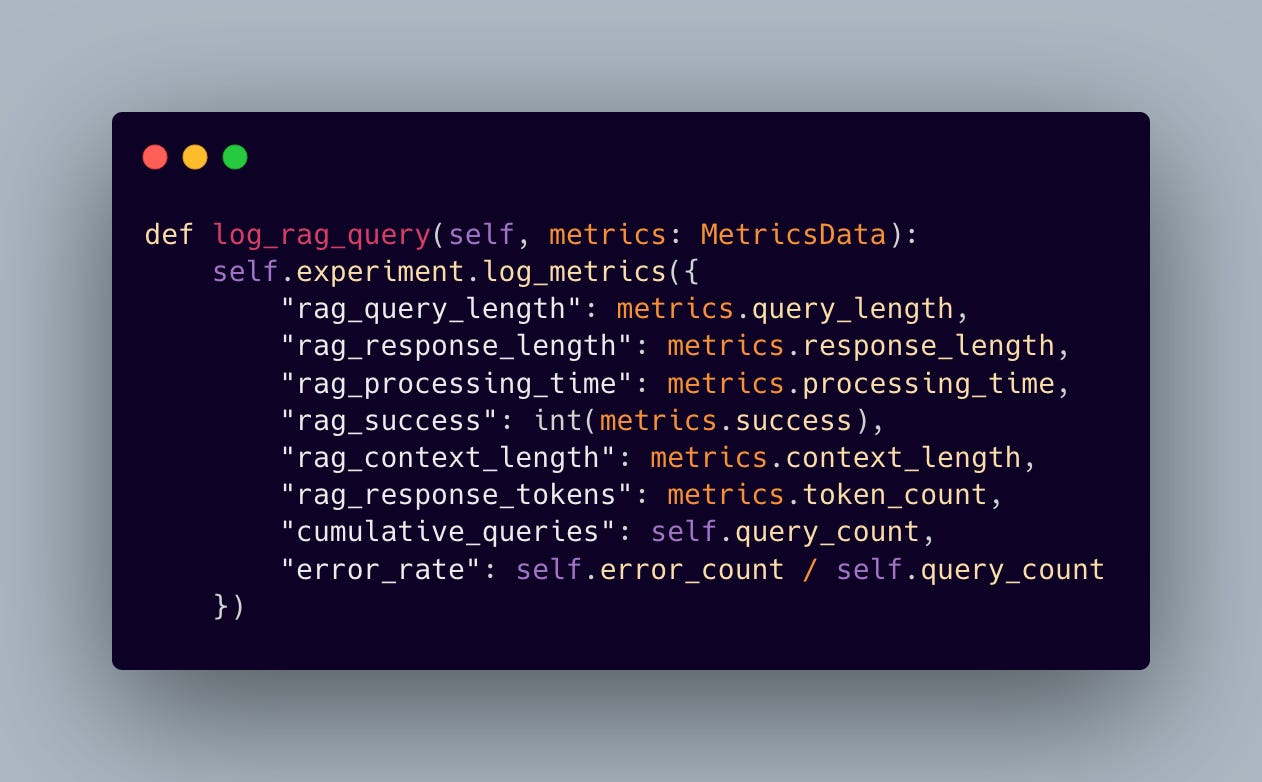
Key features include:
Real-time performance monitoring
Hourly aggregation of metrics
Error rate tracking
Session-level statistics
And for our second tool, the paper lookup tool
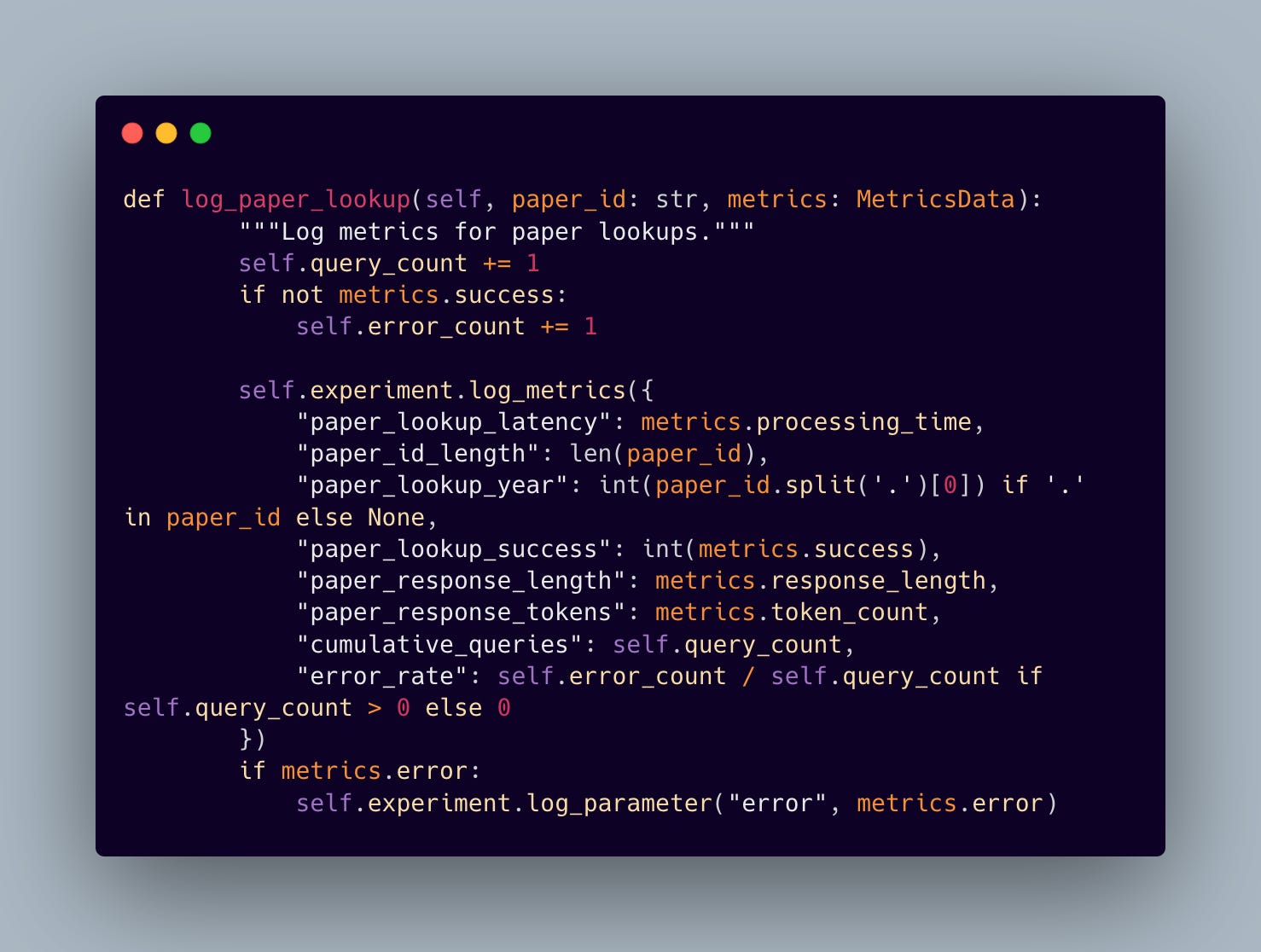
Context retrieval performance
Token usage analytics
Response generation times
Semantic search accuracy:
2.3 The Power of Real-Time Insights
CometML Opik turns metrics into real-time, actionable insights. Instead of just collecting data to look at later, we’re creating a live dashboard that does the heavy lifting for us. Here’s how it helps:
Spot performance bottlenecks as they happen
Track the system’s progress with cumulative stats
Catch patterns in error rates and processing times
Keep an eye on token usage to save on costs
Understand how users are interacting
This isn’t just about monitoring—it’s about improving. If processing times spike or error patterns look off, we can jump in right away to fix it. It’s like having a co-pilot constantly scanning for ways to make things better.
With this kind of visibility, we can keep fine-tuning, optimizing, and improving every interaction. CometML Opik’s visualization tools make all these metrics simple and clear, so both engineers and stakeholders can turn data into actionable insights. It’s all about driving continuous improvement in our agentic graph RAG system!
3. Agent Architecture
3.1 The Core RAG Architecture
Our system is built on a RAG implementation that takes a different approach from the usual methods. Instead of handling retrieval and generation as separate tasks, we’ve designed a unified system that stays aware of how it’s performing and adapts to different levels of query complexity.
At the core of it all is our RAG service, which combines vector-based retrieval with LLM-powered generation:

The initialization process sets up the key components and gets comprehensive metrics tracking in place—a must-have for production deployments. This setup gives us tight control over both the retrieval and generation phases while gathering important telemetry data.
But the real highlight? The question-answering pipeline. That’s where the magic really happens:
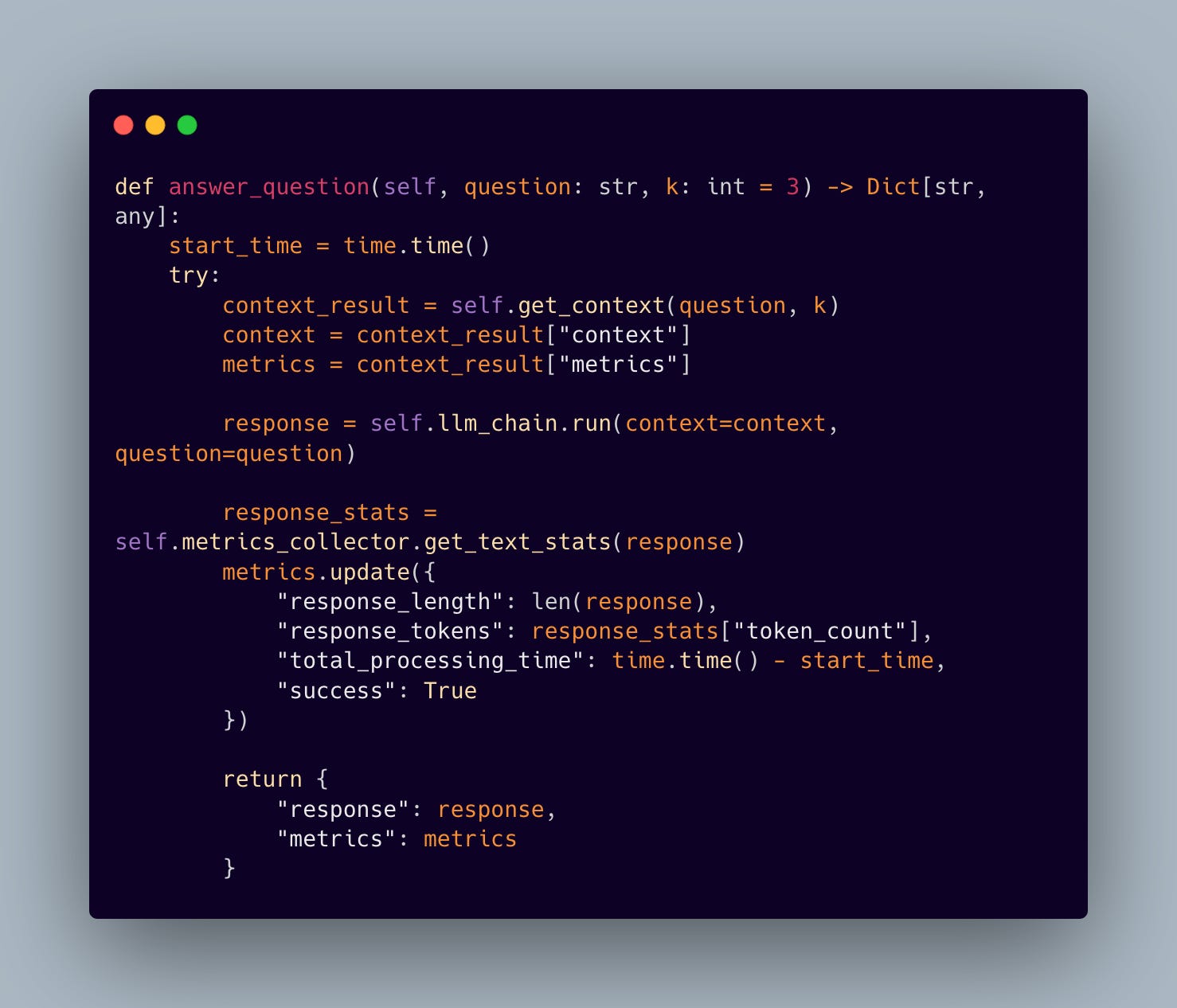
The pipeline orchestrates retrieval and generation, all while maintaining detailed performance metrics. Each query triggers a cascade of operations: context retrieval, response generation, and comprehensive metric collection. This level of instrumentation proves invaluable when optimizing system performance.
3.2 Paper Lookup Tool
The paper lookup service is built on a robust Neo4j graph database integration, enabling complex relationship queries and efficient metadata retrieval. What sets this implementation apart is its paper ID extraction system:
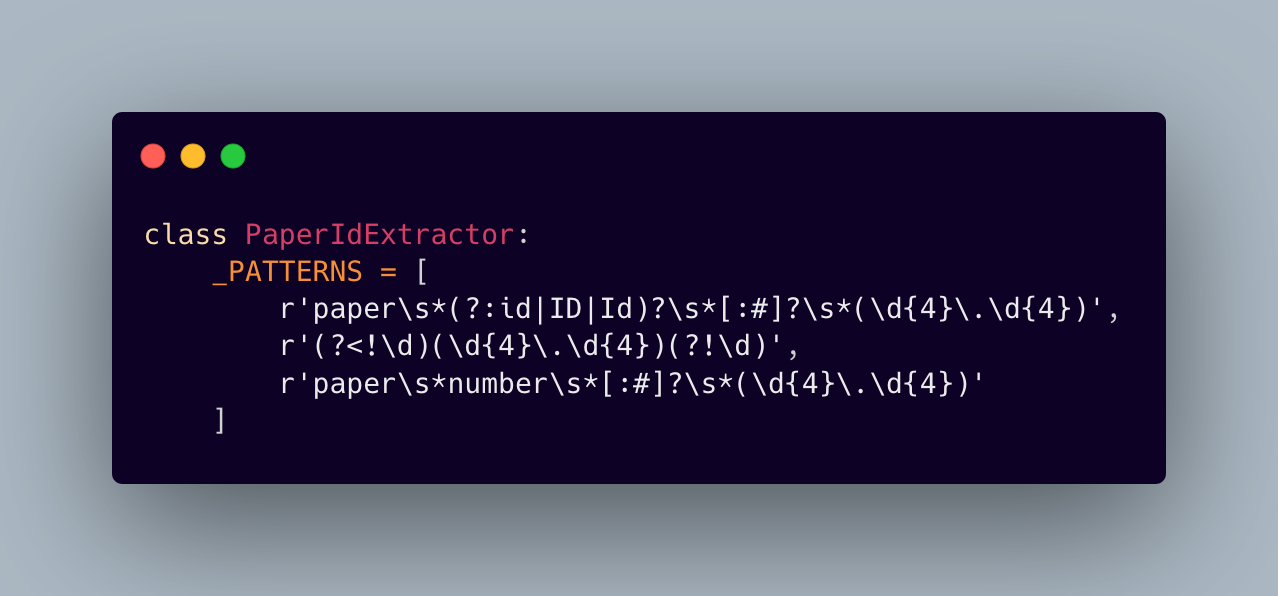
This pattern-matching approach allows our system to handle various formats and styles of paper ID references, making it more resilient to different query patterns.
3.3 Data Models and Structure
The backbone of our paper retrieval system is a well-structured data model:
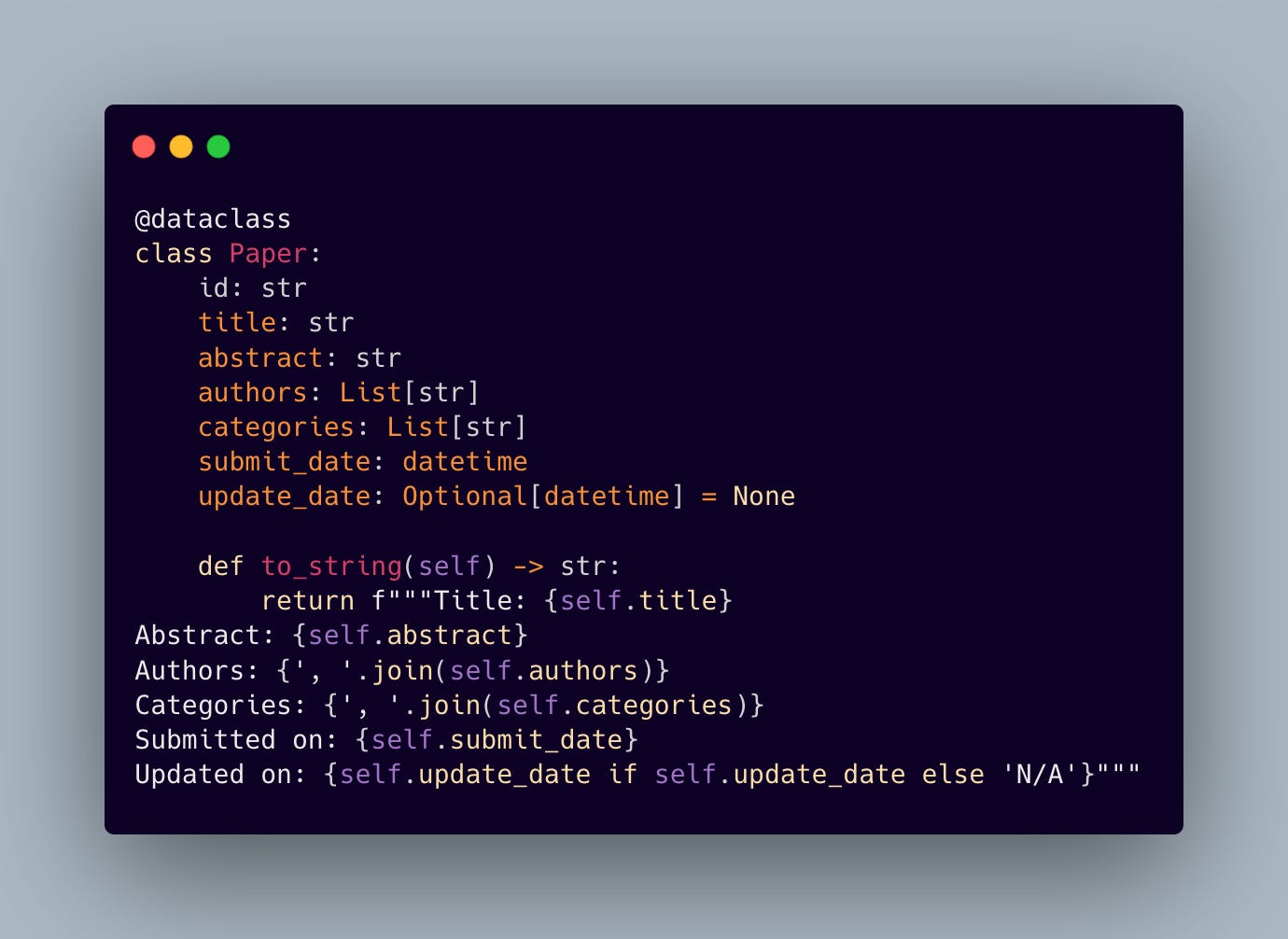
This structured approach ensures consistent data representation and enables rich metadata tracking through CometML Opik.
4. Agent Integration Through Tools and CometML Opik Integration
Modern RAG systems need to interface seamlessly with autonomous agents. We’ve achieved this through a carefully designed tool interface:
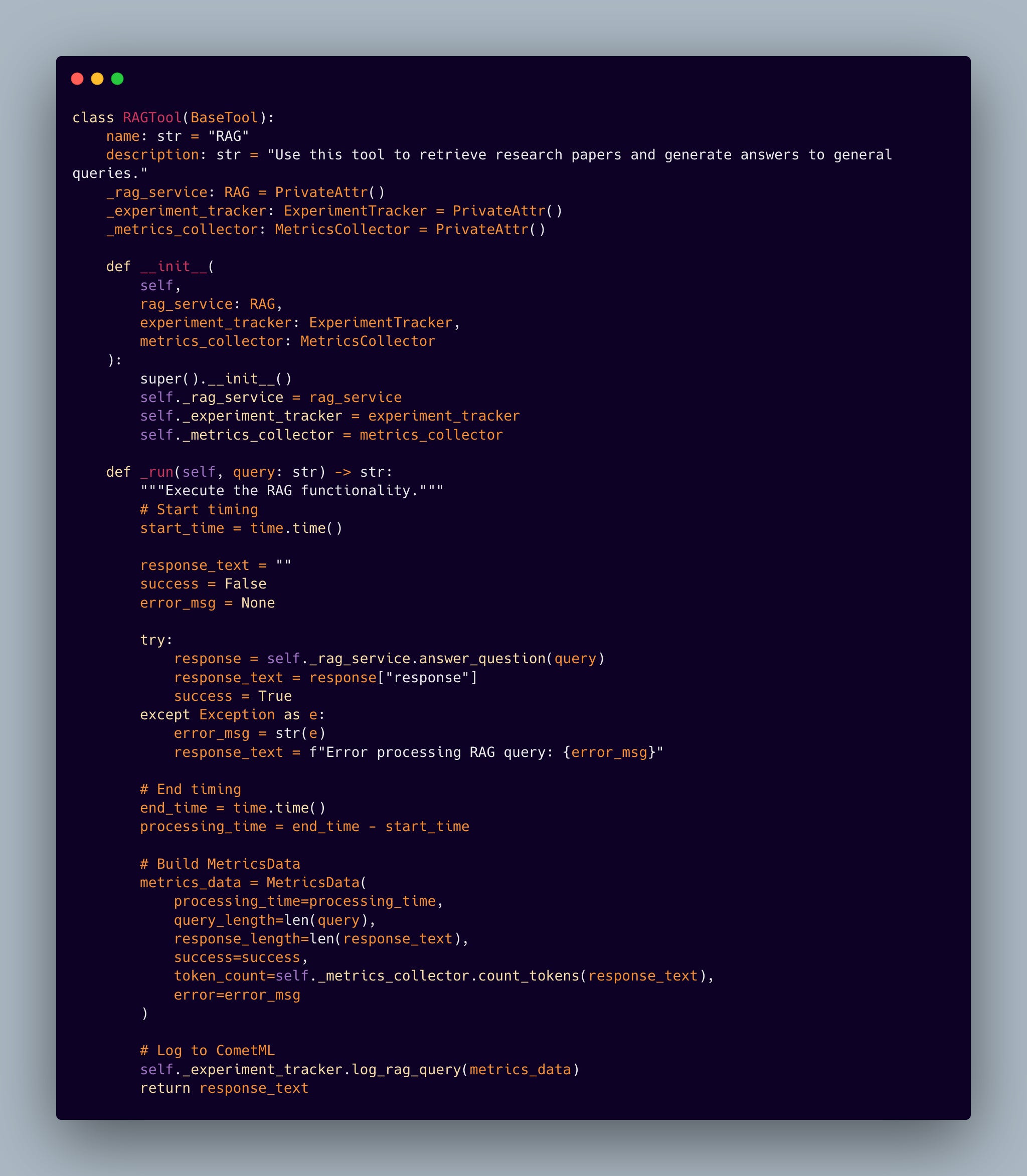
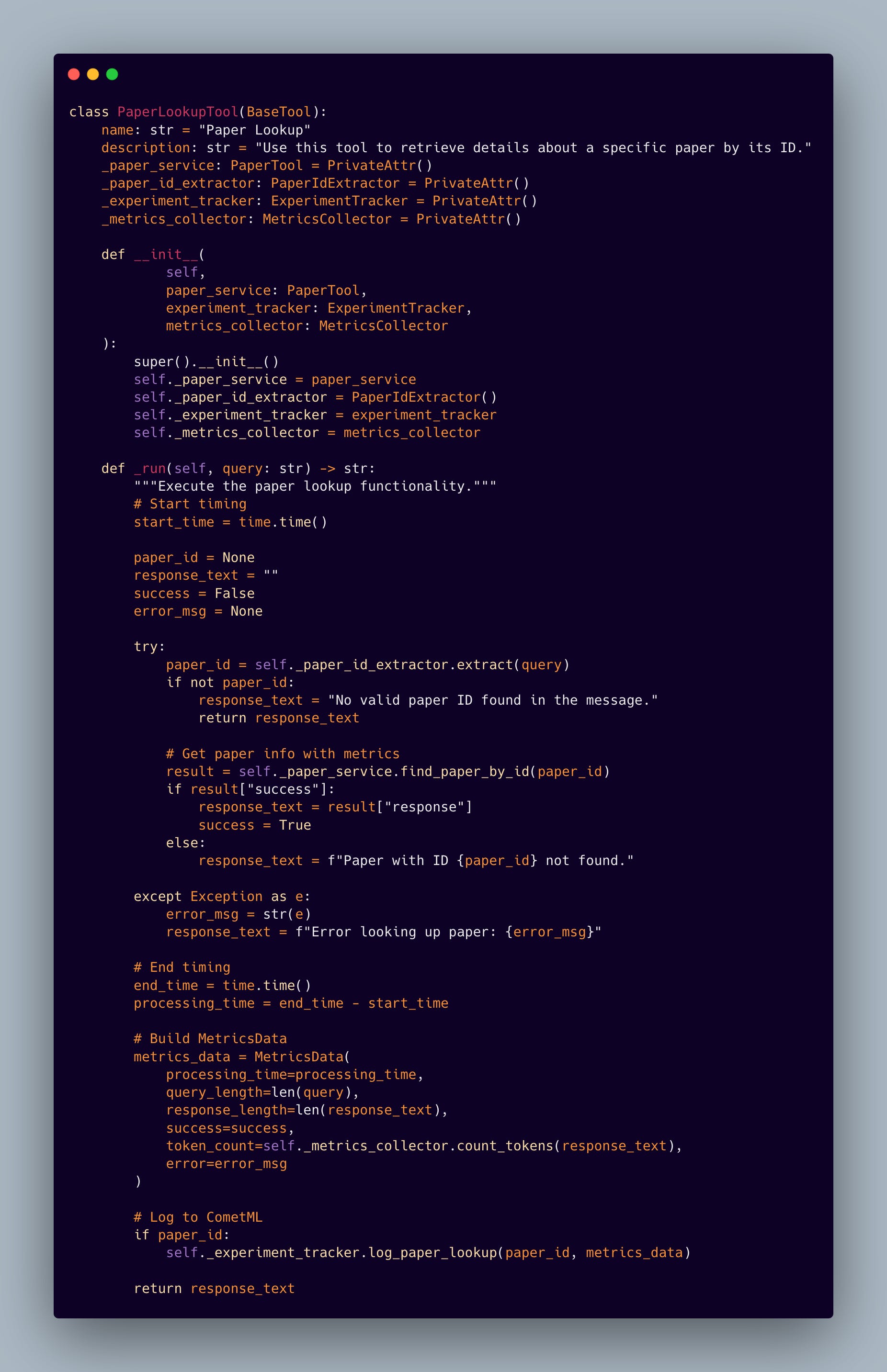
This tool abstraction enables autonomous agents to leverage our RAG and paper lookup tool system while maintaining clean separation of concerns. The implementation handles error cases gracefully while preserving the rich metadata needed for performance analysis.
5. Intelligent Tool Orchestra
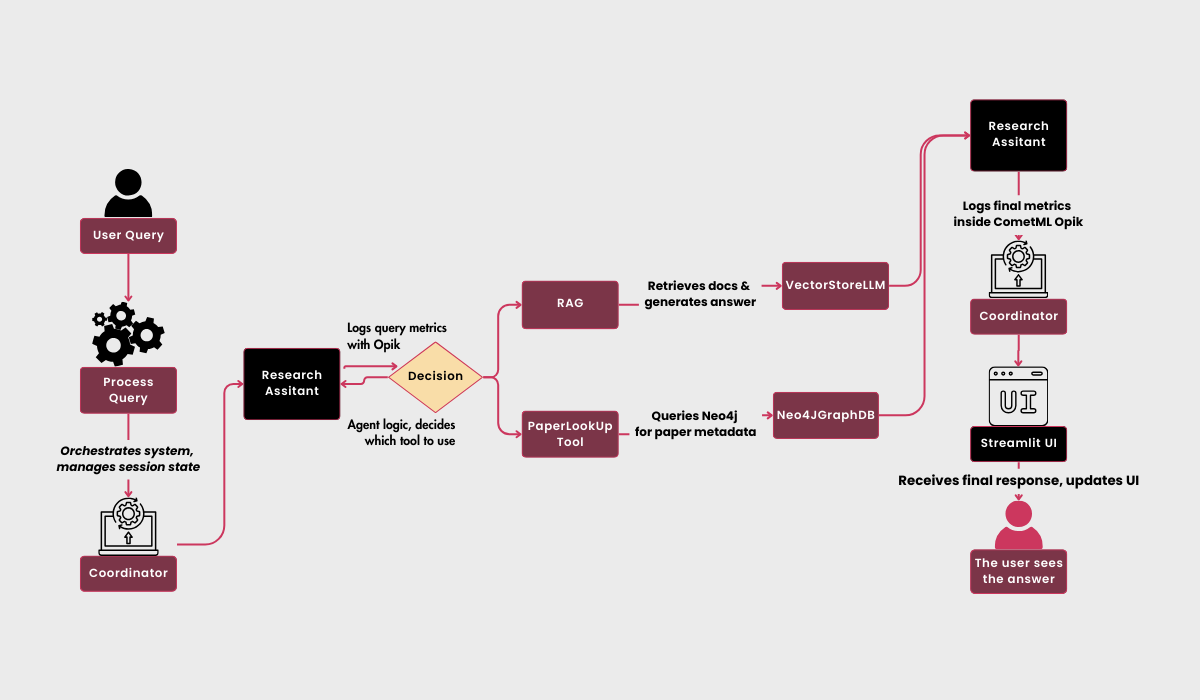
Our system’s intelligence stems from its dual-tool architecture: the RAG service and a paper lookup mechanism. Let’s examine how these tools work together to provide comprehensive research capabilities.
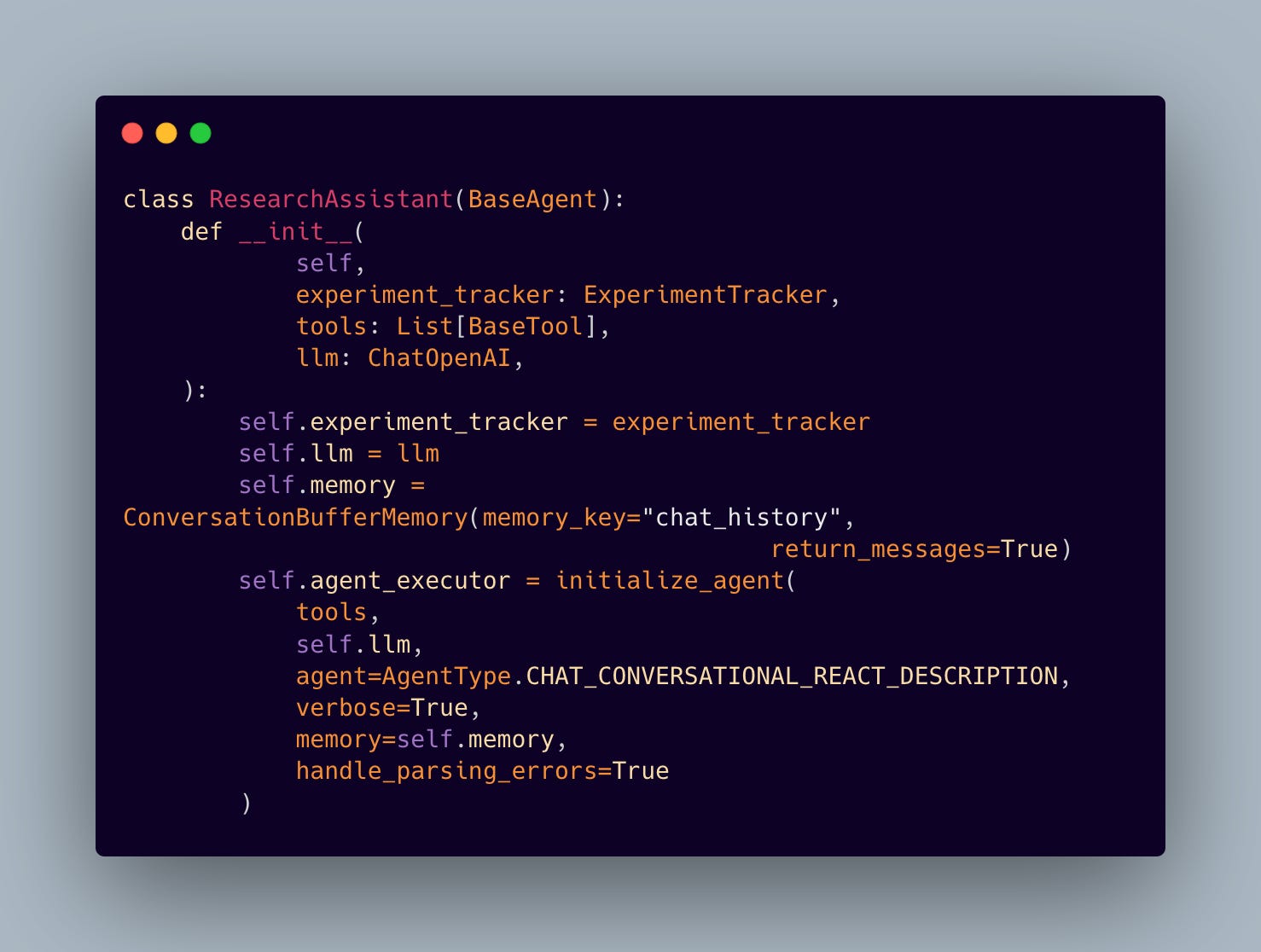
The Research Assistant dynamically chooses between semantic search via RAG and precise paper lookup based on the query context. This decision-making process is enhanced by conversation memory and comprehensive metric tracking.
For example the assistant can decide which tool to use:
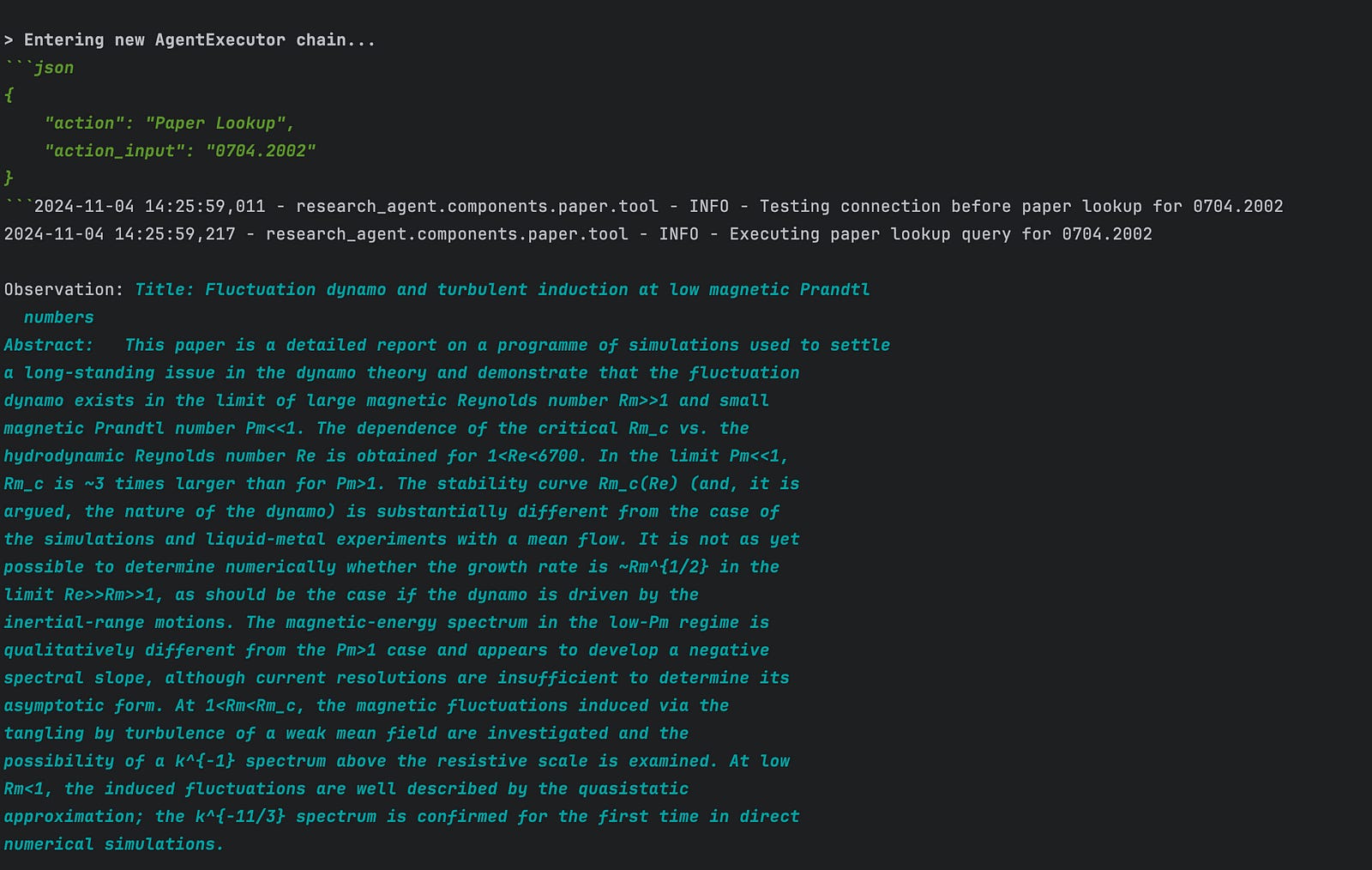
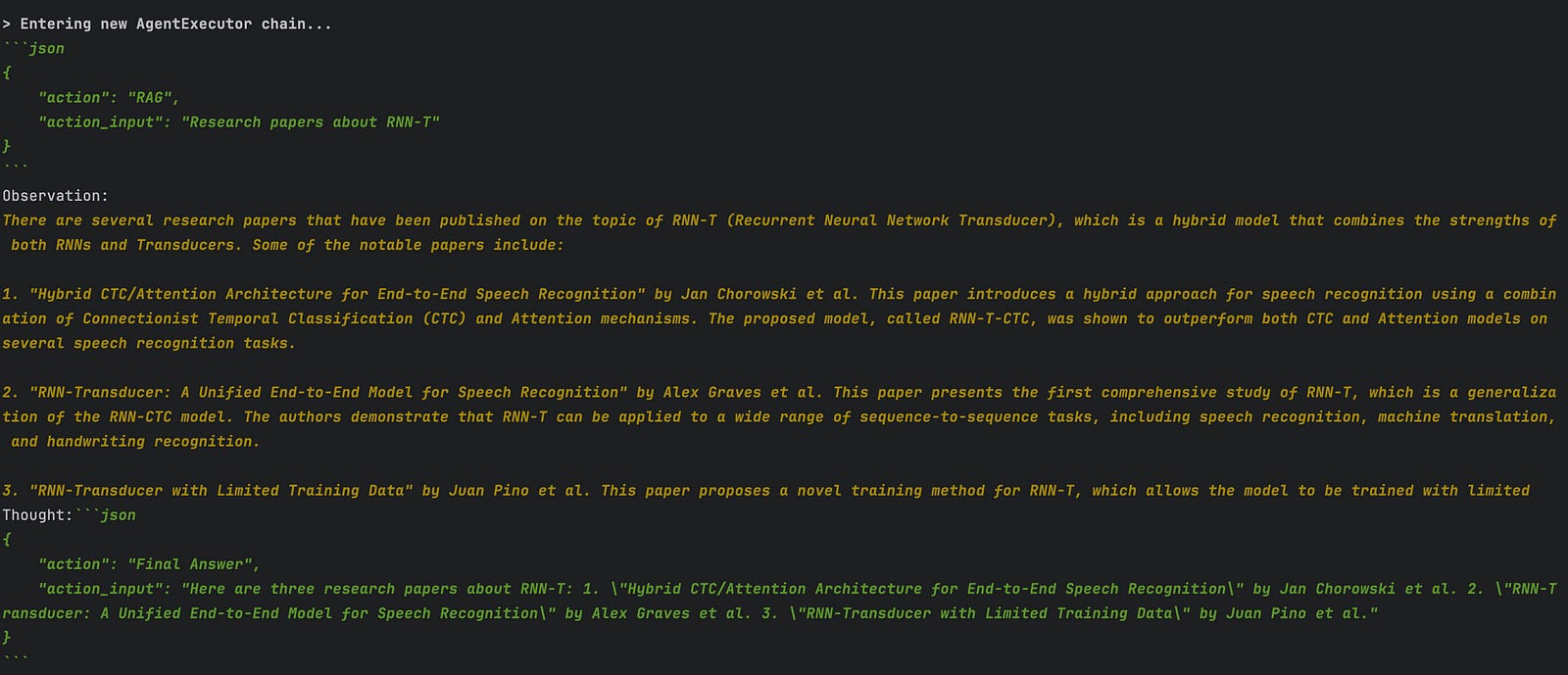
And in case that neither of the following can be used it just fallbacks to the basic LLM:
6. System Orchestration: The Coordinator Pattern
Our system is built around an orchestration layer that ties everything together seamlessly. Using the Coordinator pattern, we handle things like initialization, resource management, and interaction flow while keeping track of everything with CometML Opik.
6.1 Orchestrated Initialization
The Coordinator class serves as our system’s conductor, carefully initializing each component in the correct order:
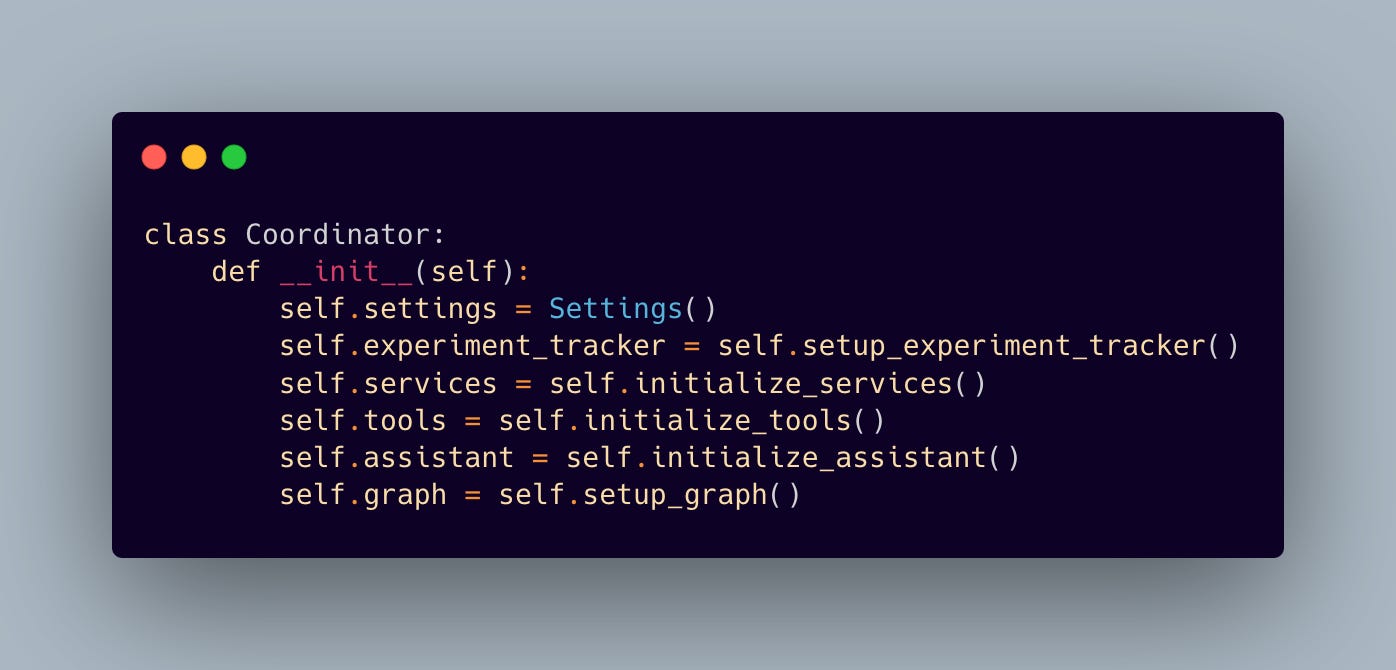
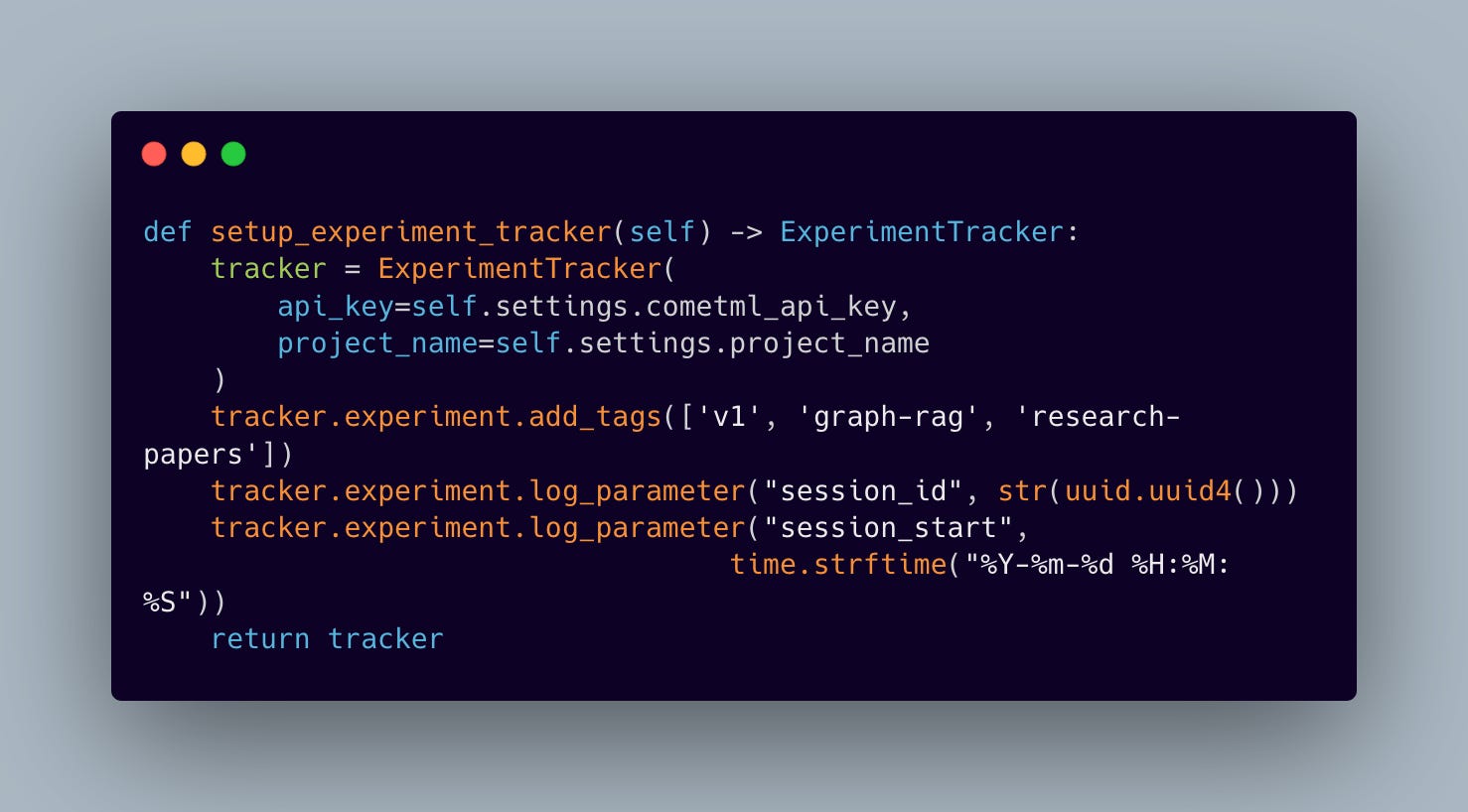
Every setup step has a purpose, making sure everything is ready to go when needed. For example, the experiment tracker gets set up first so it can start capturing metrics right from the start:
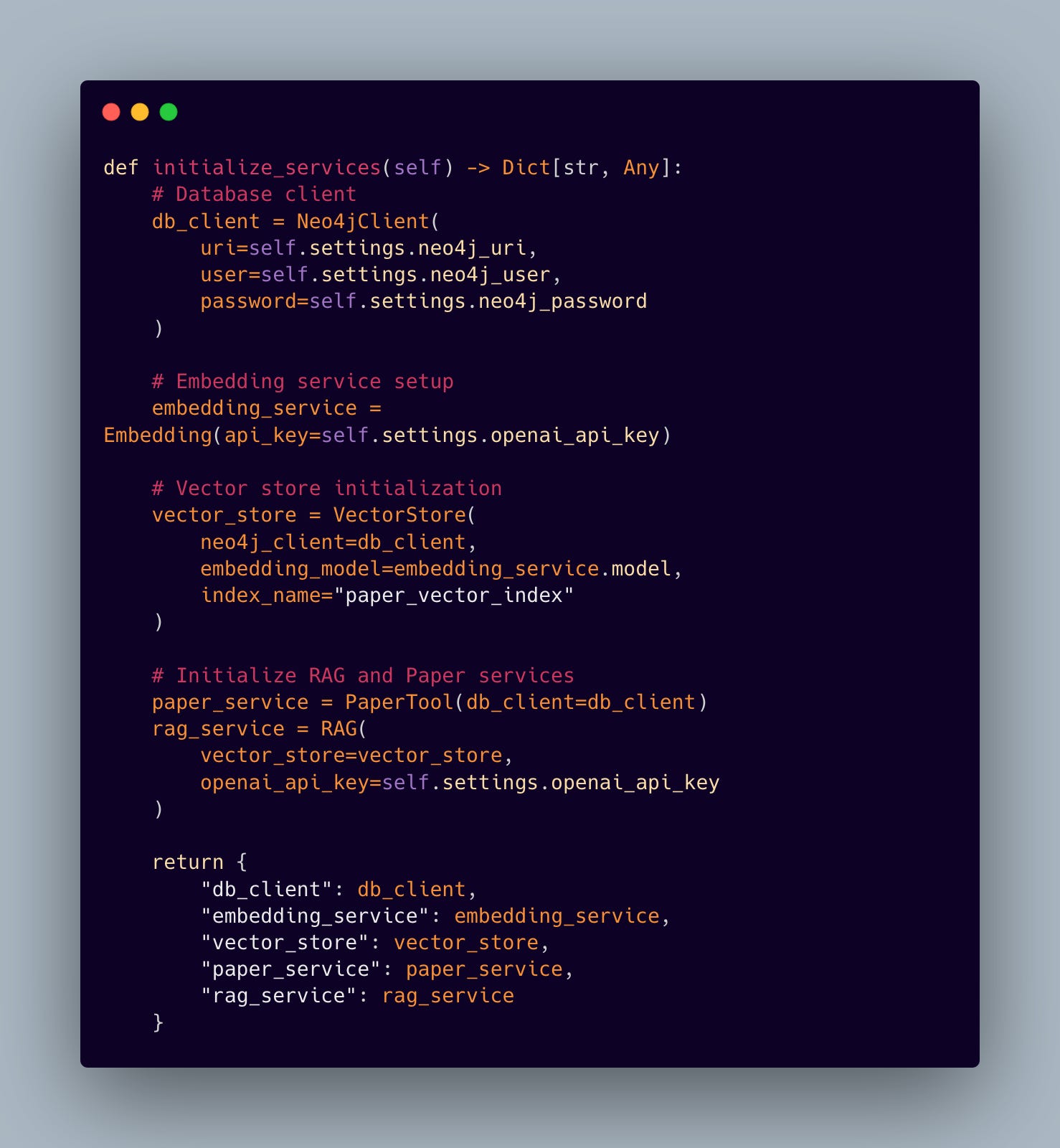
6.2 Service Layer Integration
The service initialization layer demonstrates how we bring together our various components into a cohesive system:
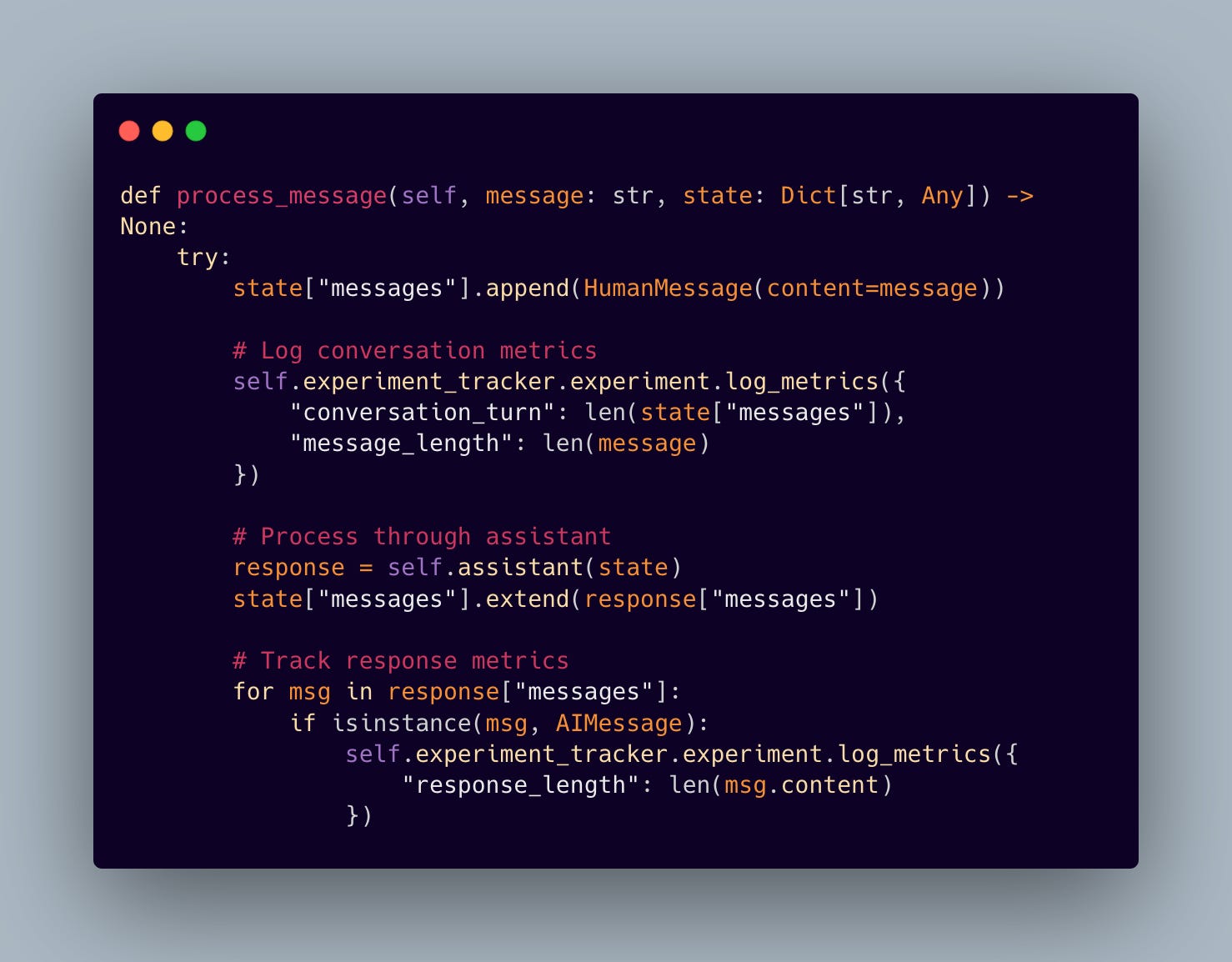
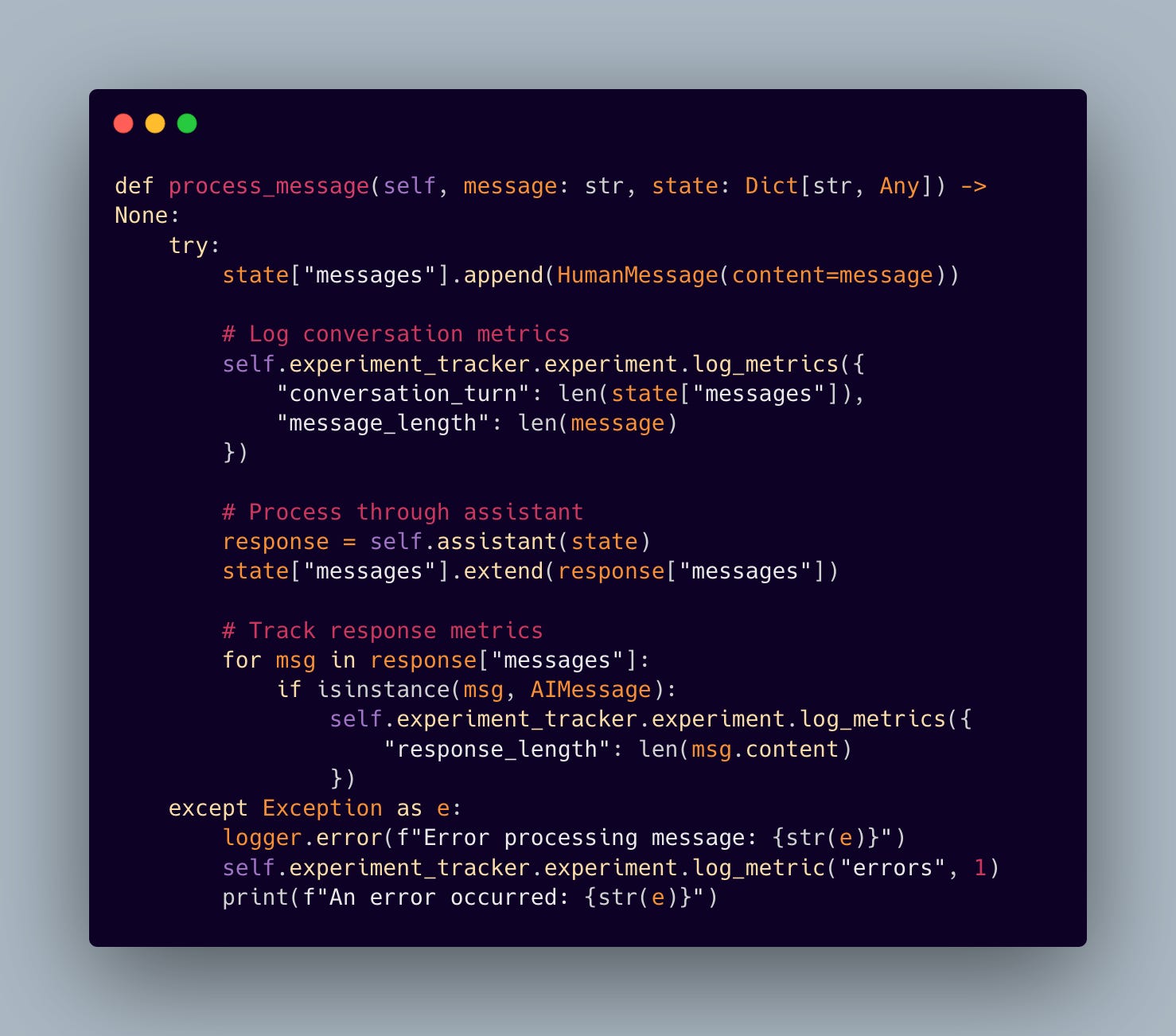
6.3 Intelligent Message Processing
The Coordinator implements message processing that maintains conversation state while collecting valuable metrics:
6.4 Resource Lifecycle Management
One of the most important aspects of production systems is proper resource management. Our Coordinator implements careful cleanup procedures:
6.5 Production Benefits of Coordinated Architecture
This approach comes with some great benefits:
Smooth Start-Up: Everything gets initialized in the right order, with dependencies handled seamlessly.
Full Visibility: With CometML Opik, you can track every part of the system in action, from start to finish.
Efficient Resource Use: Resources are allocated and cleaned up properly, so nothing goes to waste.
Built-In Resilience: Errors are handled in a structured way to avoid bigger issues down the line.
Consistent State: Conversation state and system metrics stay on track throughout the session.
The Coordinator pattern pulls all our tools together into a reliable, production-ready system. With CometML Opik’s observability platform, we can monitor, optimize, and manage every component effortlessly.
7. Conclusions
We’ve built a powerful Research Assistant system by combining a knowledge graph, vector embeddings, and an intelligent agent-driven framework. It’s designed to be both high-performing and super adaptable. With integrated metrics from CometML Opik, you get real-time insights for quick optimizations and a clear picture of the system’s health. By using smart orchestration patterns and solid data ingestion, this setup makes scaling academic research easier than ever. In the end, this system not only improves the user experience but also sets the stage for exciting advancements in Retrieval-Augmented Generation and AI-powered data exploration.
🫵🫵🫵
Enjoyed this breakdown of the core RAG challenges?
Make sure you don’t miss the rest of our journey. We’ll explore how graphs and agentic models can revolutionize retrieval, ensuring you’re equipped with the latest advancements in AI-driven knowledge exploration.🔗 Check out the code on GitHub and support us with a ⭐️