
$0.00. No Gimmicks. The first real STT guide for kids’ voices on edge devices.
Everyone else sells vague theory for $49. We’re giving away real engineering, code and code for free.




What we’ve been doing for the past few months
At last, here we are! One day before the official launch of “Fine-Tuning STT Models for Edge Devices”, the eBook that applies advanced engineering practices to raw and unfiltered audio data of kids blabbering and turns it into a conversational experience.
How it all started
We love researching anything new, and we came across a subject about STT optimized for children's voices. It was like gold for us, so interesting and underrated that we wanted to dig deeper.
We planned to create a series of articles on this subject as we learned more. However, after some time, our research became scattered, fragmented and just disorganized.
So we organized and a long meeting later we decided: we’ll talk about the industry, code, deep tech, why we cannot find information online, why this topic is not widely discussed, and why it is so hard to implement. We had a lot to explain and much to say.
Creating an eBook didn’t seem so scary anymore. We had a plan and everyone had a role to fill. Research continued, code was beginning to exist, design went underway and the marketer had a clear-cut campaign plan (that was 2 months ago).
Now we’re proud to show you the results of months of hard work and dedication.
The market in which we dip
The scary part about this eBook isn’t that it’s our first or that we’ve never done something like this before, it's whether people will actually read it.
During our research, we couldn’t find anything similar. It seemed fine until our marketer started wondering why this topic wasn’t being discussed. The subject is revolutionary and new, but it’s also hard, costly, and requires a lot of effort. Our concern shifted from people not being interested to the idea that it’s so difficult that people simply don’t talk about.
Maybe the industry isn’t ready for this kind of investment, it’s risky, and finding people willing to learn and work on it is too tough. There isn’t a STT model adaptable for children’s voices yet because most systems are trained on adult voices, and there’s limited data on children’s speech.
In contrast to TED Talks and podcasts, where speakers are clear and easy to understand, children’s voices vary widely in pitch, pronunciation, and rhythm, making it extra challenging to develop an accurate model.
This eBook serves a different purpose now. A beginning for research and considerations in this field. An educational resource for those who find themselves in the same position we did. An example of HOW with a practical application instead of theory, theory and more theory.
On writing an eBook for the first time
“I started this project when I realized that standard speech-to-text systems just didn’t handle children’s voices. I had a messy dataset to work with which I refined over time by cleaning and normalizing the audio then testing out automated transcriptions. What you will see is the final product, a product which took countless hours, even a few full days out of my lifespan.
Instead of diving straight into complex fixes, I focused on the core concept: making the model understand real kids’ speech. I fine-tuned a pre-trained model and explored ways to shrink it efficiently without losing its performance.
It was never about getting it perfect, because we wanted to show that even from nothing, I mean it, completely nothing, you can build everything if you put your mind to it. It’s not perfect we know it. Are there certain areas that need improvement? Definitely.
The idea is that we build a working E2E solution for a problem that is not spoken about enough. And if you have an idea, go build it! Get out there, and show it in any type of content, let it be an ebook, article, YouTube video, even OnlyFans if you want.
I would go back to each chapter again and again. Every time I hit a problem in the code, I’d tweak things and rework the explanation until it finally clicked. This back-and-forth helped not only with the technical details but also in making the eBook easy to follow.
It was a lot of trial and error, but it made all the difference in turning rough ideas into something clear and practical for everyone.” - Stefan Colcier, the author of this eBook.
Who is this book for?
This isn’t another polished tutorial that assumes you’ve got the perfect dataset and a dozen GPUs lying around, because we also didn’t. This book is for the ones in the trenches dealing with unusable audios and messy data.
If this sounds like you, you found the right resource:
You need to turn some unlabeled audio into a usable dataset by yourself;
You're curious how to fine-tune state-of-the-art models like Wav2Vec2 for real, not just for the benchmarks;
You need to shrink a large model to run on limited hardware while keeping performance good enough for production;
You want to go from model to actual product: REST API, edge-friendly, privacy-first, deployed and usable;
You’re building tech for noisy, resource-limited environments like schools, rural areas, or offline-first apps';
You care about accessibility, equity, and inclusion, and believe that good AI should serve everyone, not just the average adult user.
Check out the code in the 🔗 GitHub repo. Leave us a ⭐️ if you love what we do!
The following snippet is taken from the Chapter 1: Introduction.
Why is child voice detection on edge devices so hard?
Children’s speech varies significantly in pitch, speaking speed, and vocabulary. When you combine these factors with the hardware limitations of edge devices, where CPU power, available memory and battery life are all constrained, you end up with a perfect knot of technical challenges for STT models.
Achieving both real-time performance and decent accuracy under these conditions requires tailored optimization strategies that aren’t needed in conventional STT made with and for adults voices on a cloud-based setup.
High-level solution
In this eBook, we tackle a significant challenge: optimizing speech-to-text (STT) models for child voice recognition on resource-constrained edge devices. Children's voices, with their higher pitch, irregular pronunciation, and unpredictable speech patterns, have long been a blind spot for mainstream STT systems trained on adult speech. This creates an accessibility barrier for countless educational applications where voice interaction would be most beneficial.
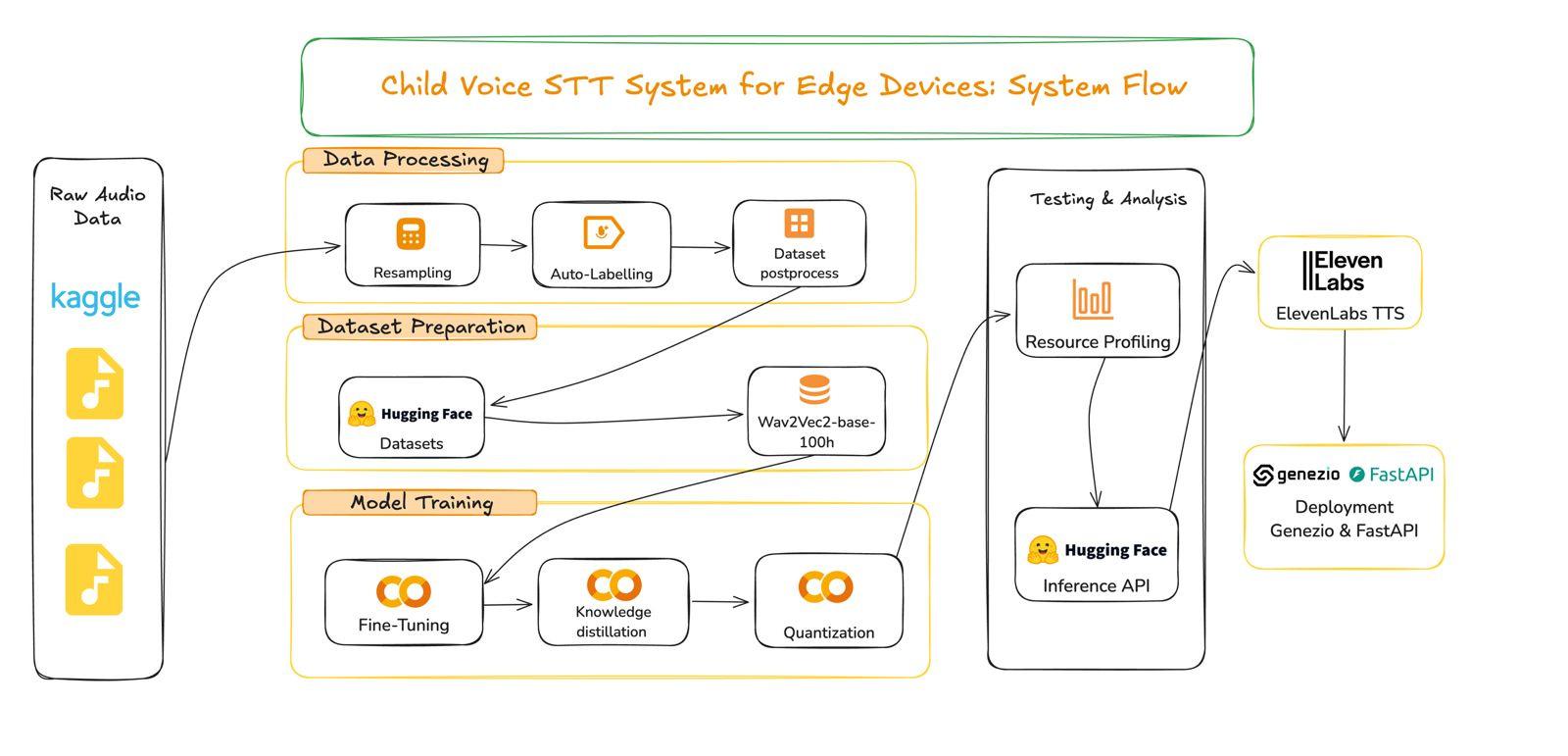
Our solution transforms generic STT models into specialized tools for pediatric speech recognition through a comprehensive end-to-end pipeline:
Data preparation and labeling: Starting with unlabeled audio recordings, we create a high-quality dataset with accurate transcriptions;
Model fine-tuning: Adapting the Wav2Vec2 architecture to recognize the unique characteristics of children's speech patterns;
Model optimization: Using knowledge distillation and quantization to reduce model size by 60% while maintaining accuracy;
Deployment: Implementing the model in a complete end-to-end solution with FastAPI endpoints and serverless deployment using Genezio.
The Reality of Limited Resources
The elephant in the room for most STT projects is data, or rather, the lack of it. We frequently encounter scenarios where specialized STT solutions are needed, but collecting or labeling large-scale data is prohibitively expensive, impractical or unethical. This is especially true for child speech datasets. [10]
Simultaneously, many applications must run on low-end devices in classrooms or rural areas, where cloud-based solutions and hefty memory footprints aren't feasible. Most educational environments lack the infrastructure for reliable cloud connectivity, making edge deployment essential.
This reality drove our investigation: could we begin with unlabeled data, create a labeled dataset, then fine-tune a compact STT model that still handles the complexity of child speech under tight hardware constraints?
Our process
Starting with a small Kaggle dataset of child speech recordings with no transcriptions, we built a complete pipeline:
We analyzed and pre-processed the audio for consistency;
We automatically labeled the data using SpeechBrain's Conformer model;
We validated, cleaned, and normalized the transcripts;
We fine-tuned a Wav2Vec2 model on this prepared dataset;
We applied knowledge distillation and quantization to reduce the model size while preserving accuracy;
We rigorously tested the model's performance and resource consumption on constrained hardware;
We built a complete end-to-end solution with RESTful endpoints using FastAPI;
We deployed the entire application using Genezio's serverless platform for easy scaling and maintenance.
This eBook provides a complete guide on tackling this kind of real-world challenge with less-than-perfect conditions, a scenario much closer to what practitioners face than the idealized examples in many tutorials.
End snippet.
Ending notes
If any part of this resonated, messy data, edge devices, inaccessible tech, or just the raw chaos of building something from scratch → this eBook is for you.
🚀 The official launch is tomorrow.
We’re giving it away for FREE to our early subscribers. No strings. Just ideas, code, and hard-won lessons we wish someone had told us.
PS: Don’t forget to invite your friends to subscribe also (if you don’t have any gift idea)
Check out the code in the 🔗 GitHub repo. Leave us a ⭐️ if you love what we do!
Tomorrow we’ll send out an email to all subscribers with instructions on how to get the eBook FOR FREE. So if you didn’t already do this,